Building AI Products—Part II: Task-Oriented vs. Component-Oriented Pipelines
A while back, I kicked off a three-part series on how we built an AI-powered Chief of Staff for engineering leaders—a product that scaled to 10,000 users and later became the foundation of Outropy.
The first article covered the back-end architecture powering our AI agents. In this second installment, let’s explore inference pipelines—the beating heart of any AI system, agentic or not—through the lens of hard-won engineering lessons.
Next time, I’ll discuss how we built agents that leverage these pipelines internally and coordinate with each other to power our application.
Are Inference Pipelines Just RAG?
If you’ve been reading about AI agents lately, you’ve probably noticed the overwhelming hype. Discussions often treat “agents” as if they’re magical, glossing over how they actually work. The reality is that agents—and any AI-powered system—perform tasks using inference pipelines.
At its core, an inference pipeline takes raw input—such as a user query or data—and transforms it into meaningful output based on user and developer-defined instructions and constraints. It’s the engine behind AI systems, chaining multiple steps together to produce the final output.
Technically, most inference pipelines fall under Retrieval-Augmented Generation (RAG) since they involve retrieving and incorporating relevant context before generating a response. But in practice, the term “RAG” has come to mean something much narrower—typically document-based Q&A chatbots that pull text snippets from a database and feed them into an LLM.
Inference pipelines go far beyond that. They power multi-step reasoning, task orchestration, entity extraction, workflow automation, and decision-making systems—capabilities that extend well beyond retrieving and summarizing documents.
Because inference pipelines cover a much broader range of AI workflows, I won’t be using the term RAG throughout this article. The goal is to highlight the full scope of what these pipelines can do without reinforcing the misconception that they’re limited to document retrieval.
A Recap of the App
I’ve always described our assistant as The VSCode for Everything Else because my vision was to bring the power of an IDE—like VSCode or JetBrains’ tools—to the non-coding parts of your job.
With a good IDE, I can open a Git repository I’ve never seen before and, within a few keystrokes, find where something is used, what it depends on, what might break if I change it, who wrote it, and when. That level of instant understanding makes coding faster and more efficient.
I wanted that same kind of awareness for everything outside of code. Whether I was preparing for a meeting, reading an RFC, or making a project decision, I wanted an assistant that could surface relevant context just as easily.
Our assistant was a collection of AI agents that pulled information from tools like Jira, Slack, GitHub, and Google Workspace. It learned about you, your priorities, and your projects to deliver timely, relevant insights. When it detected something you’d likely want to see, it proactively surfaced it. You could also summon relevant context on demand with Cmd+Shift+O, based on whatever was on your screen.
Here’s a slide straight from our original pitch deck:
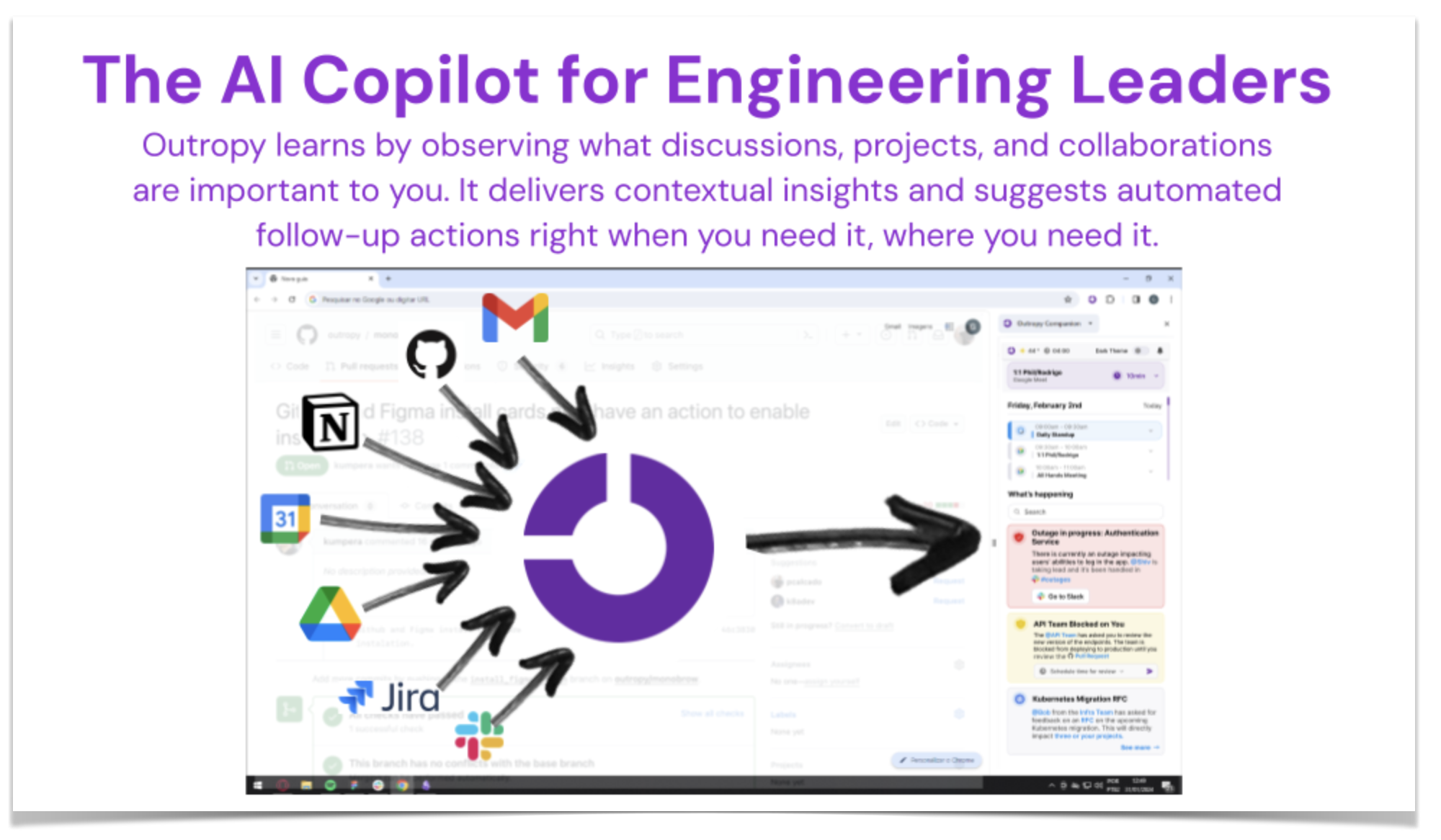
As you’d expect, integrating with countless APIs—each with its own auth, quotas, and rate limits—was a massive effort. If I were doing it today, I’d probably use a service that unifies these APIs. But surprisingly, integration wasn’t the hardest part. The real challenge was making the data useful.
One Small Feature for Users, One Giant Pipeline for Engineering
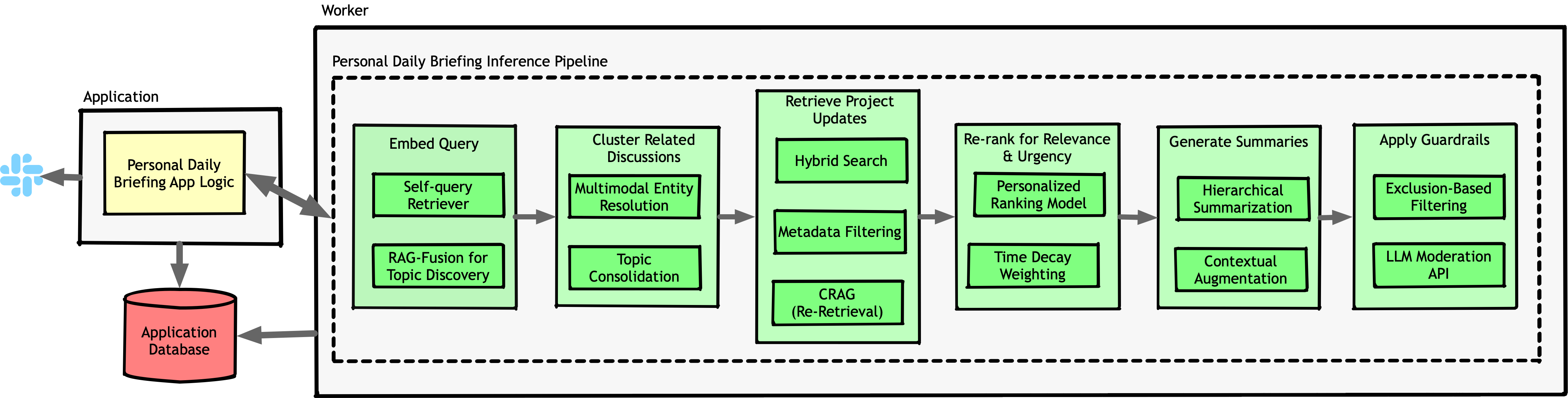
The first feature, Personal Daily Briefing, launched as a daily summary that appeared when you first became active on Slack. It surfaced the three most important and time-sensitive topics for you. It looked like this:
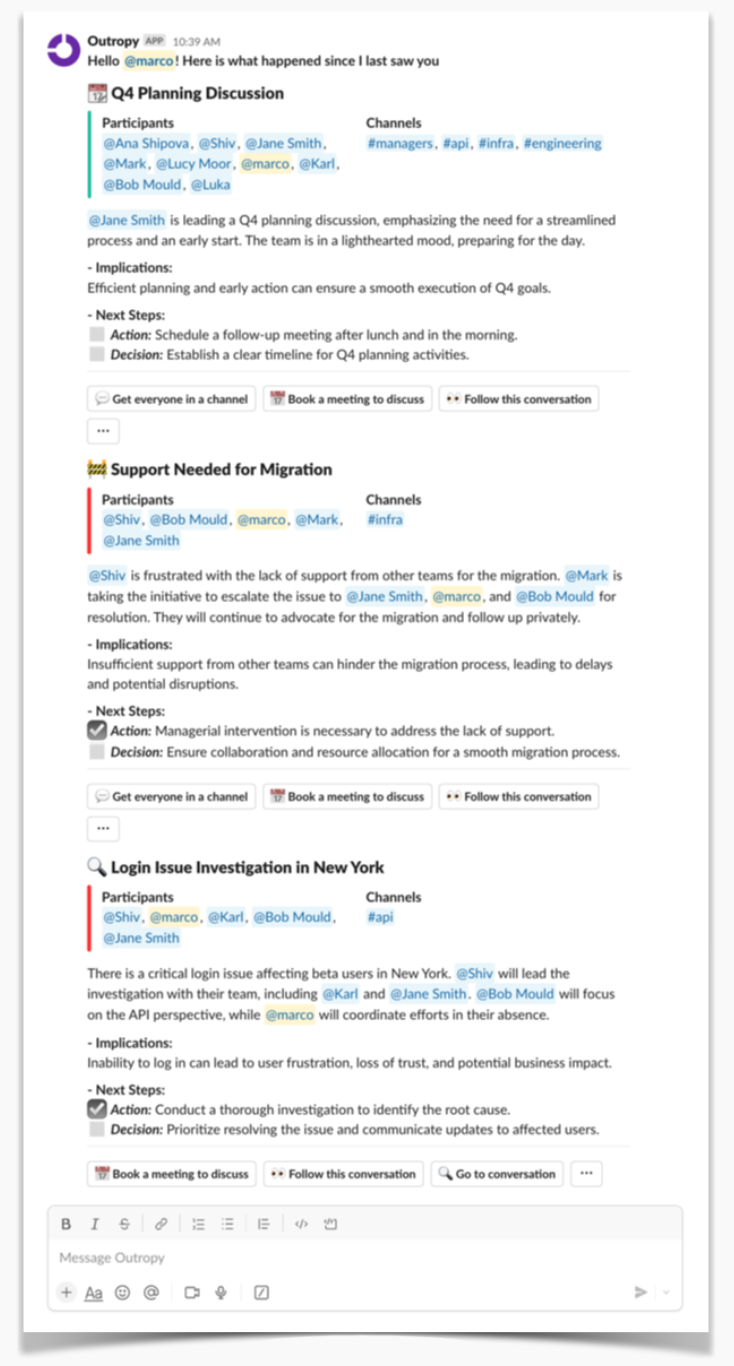
Our top priority was getting the product into users’ hands as quickly as possible. As part of our go-to-market strategy, we partnered with Slack communities for software engineering leaders. These groups provided a great test bed since their members—engineering managers, directors, and VPs—were not only our ideal customers but also deeply engaged in discussions about work.
We built the first version of this feature just two months after ChatGPT’s release, back when the entire industry was still figuring out Generative AI. That period taught us a lot about both the possibilities and limitations of these models. Some challenges were unique to that first wave of commercial models, but most still exist today. I want to share some of the most interesting ones.
In our original approach, content from Slack (and later, other tools) was stored in a Postgres database by worker processes, as described in Part I. From there, it was a two-step process:
- Find Relevant Messages
- Identify the Slack channels each user belongs to.
- Fetch all messages from those channels in the past 24 hours.
- Summarize Messages
- Create a list of channel:messages pairs.
- Send the list to ChatGPT and ask it to identify and summarize the three most important stories.
We bundled these two steps into one piece of code and made one single call to the LLM:
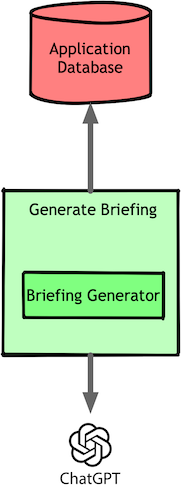
This basic approach was enough to generate that wow factor we all experienced when first using AI tools in 2022–2023. But, in a classic AI story, our naïve implementation didn’t survive real-world complications.
The first problem was context window size. Back in 2023, models had small context windows—around 4,000 tokens. Even today, with much larger windows, performance still degrades when too much irrelevant information is included in a prompt. More noise leads to worse results, no matter the model size.
Then there was the issue of writing style. Users reacted badly to briefings that referred to them in the third person or framed their own actions as if they were external events. We had to personalize the briefings—at least enough that they felt like they were written for the user.
That led us to the next challenge: relevance. Different users care about different things, and those interests evolve. Just because a project is on fire doesn’t mean everyone cares—especially if highlighting it means pushing out something more relevant. We needed a way to rank stories based on each user’s interests.
But by far, the biggest problem was duplicate summaries. Slack discussions often happen across multiple channels, meaning our system needed to recognize and merge duplicate topics instead of treating them as separate events.
To solve this, we started by analyzing the Slack channels each user belonged to and tracking the topics discussed. We boosted the relevance of topics a user had interacted with—whether through messages or reactions—to create a ranked list of subjects they cared about. This prioritized list was stored in Postgres and updated using an exponential decay algorithm to keep interests fresh.
Now that we had a way to prioritize content, we had to make the summaries more structured. The improved flow worked like this:
- Summarize Discussions in Each Channel
- Identify the Slack channels each user belongs to.
- For each channel, summarize all discussions from the last 24 hours.
- Identify which topics each discussion belongs to.
- Consolidate Summaries Across Channels
- Send the list of all discussed topics to ChatGPT.
- Ask it to consolidate and deduplicate similar topics.
- Rank Summaries for the User
- Fetch the list of topics the user currently cares about.
- Send this list with consolidated summaries to ChatGPT.
- Ask it to choose the three most relevant summaries based on user preferences.
- Generate a Personalized Summary
- Take the three selected summaries and user-specific information.
- Ask ChatGPT to generate a briefing tailored to the user’s perspective.
Our system started looking more like an actual pipeline:
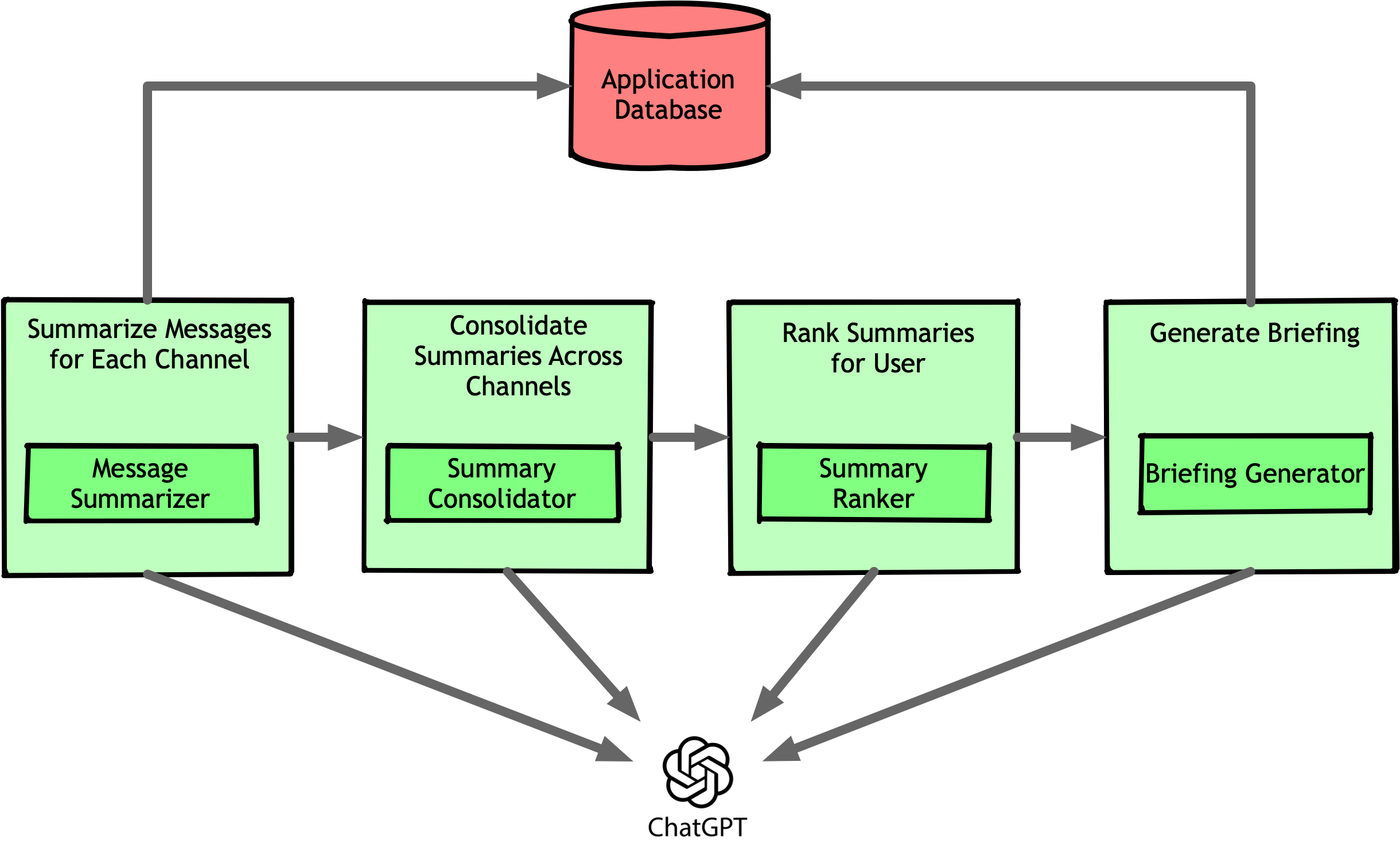
These new steps added complexity. In Part I, we tackled infrastructure challenges, but chaining LLM calls created a new kind of failure. Models don’t just retrieve data—they generate it. This means every response is a decision point, and even a small inaccuracy—whether from a flawed assumption or outright hallucination—can be treated as fact by the next step, compounding errors and making the final output unreliable.
Worse, LLMs are highly sensitive to input variations. Even a minor model upgrade or a slight shift in data formatting could cause misinterpretations that snowballed into serious distortions.
We saw plenty of weird, sometimes hilarious failures. One engineer casually mentioned in Slack that they “might be out with the flu tomorrow.” The importance detection stage flagged it correctly. But by the time the contextualization stage processed it, the system had somehow linked it to COVID-19 protocols. The final daily briefing then advised their manager to enforce social distancing measures—despite the team being 100% remote.
By the time an issue surfaced in the final output, tracing it back to the original mistake meant digging through layers of model interactions, intermediate outputs, and cached results. To prevent this, we quickly added a guardrails stage to catch nonsense before it reached the user.
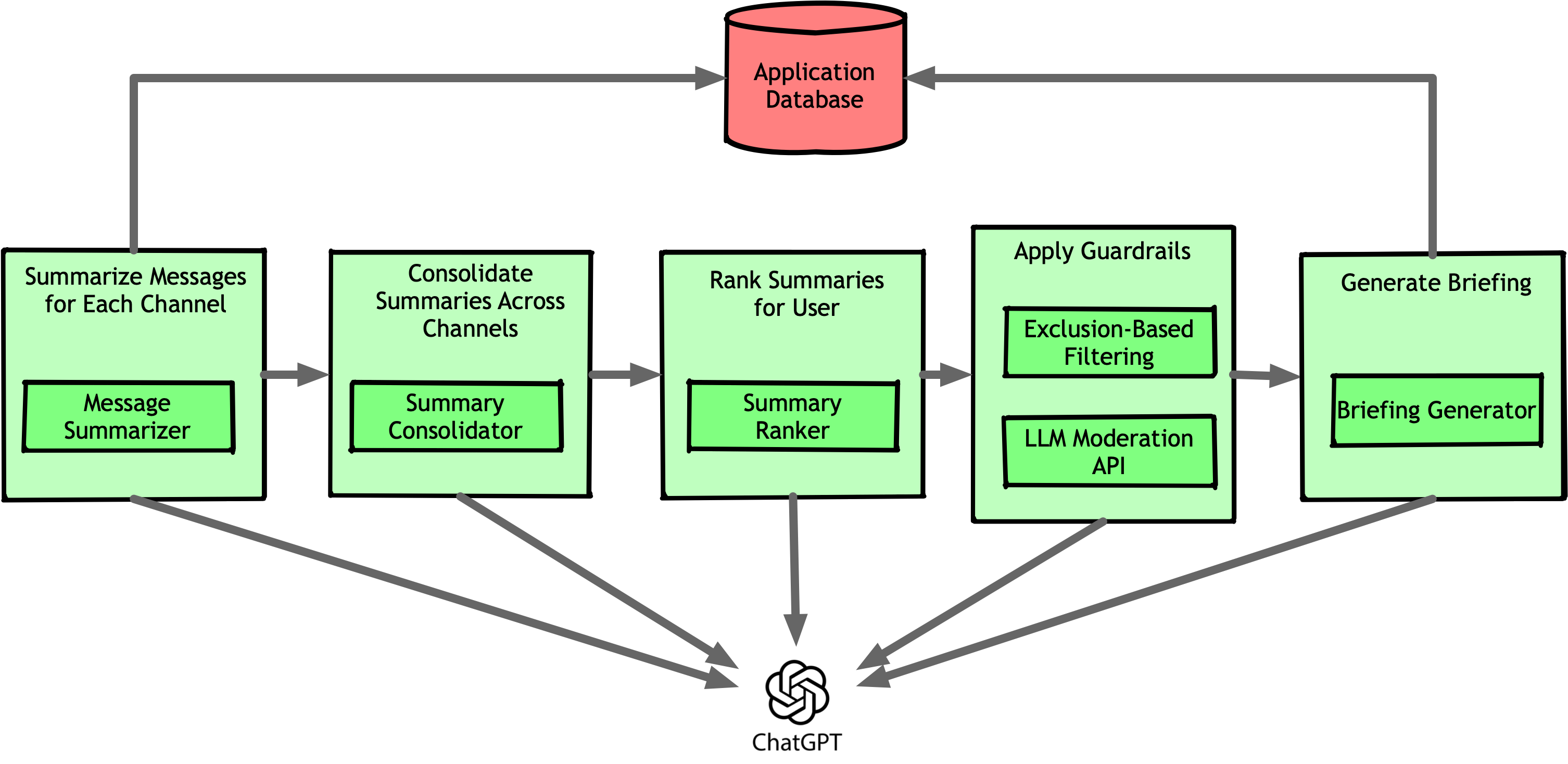
This worked well for a while, preventing us from generating the kind of nonsensical responses that erode trust in AI tools. However, our design had a major flaw: once an error was detected, the only options were to rerun the pipeline or escalate to human intervention.
As we added more users and expanded beyond Slack to tools like Figma, GitHub, and Jira, the pipeline became increasingly complex. Now, it wasn’t just about deduplicating summaries across Slack channels—we also had to recognize when the same topic was being discussed across different platforms. This required entity extraction to identify projects, teams, and key entities, enabling us to connect discussions across multiple systems.
These enhancements exacerbated the cascading error problem. It reached a point where most briefings were rejected by our guardrails and required manual review. To fix this, we added more substages to the pipeline, introducing auto-correction and validation at multiple points. Of course, this only increased the pipeline’s complexity further, and by the end, it looked something like this:
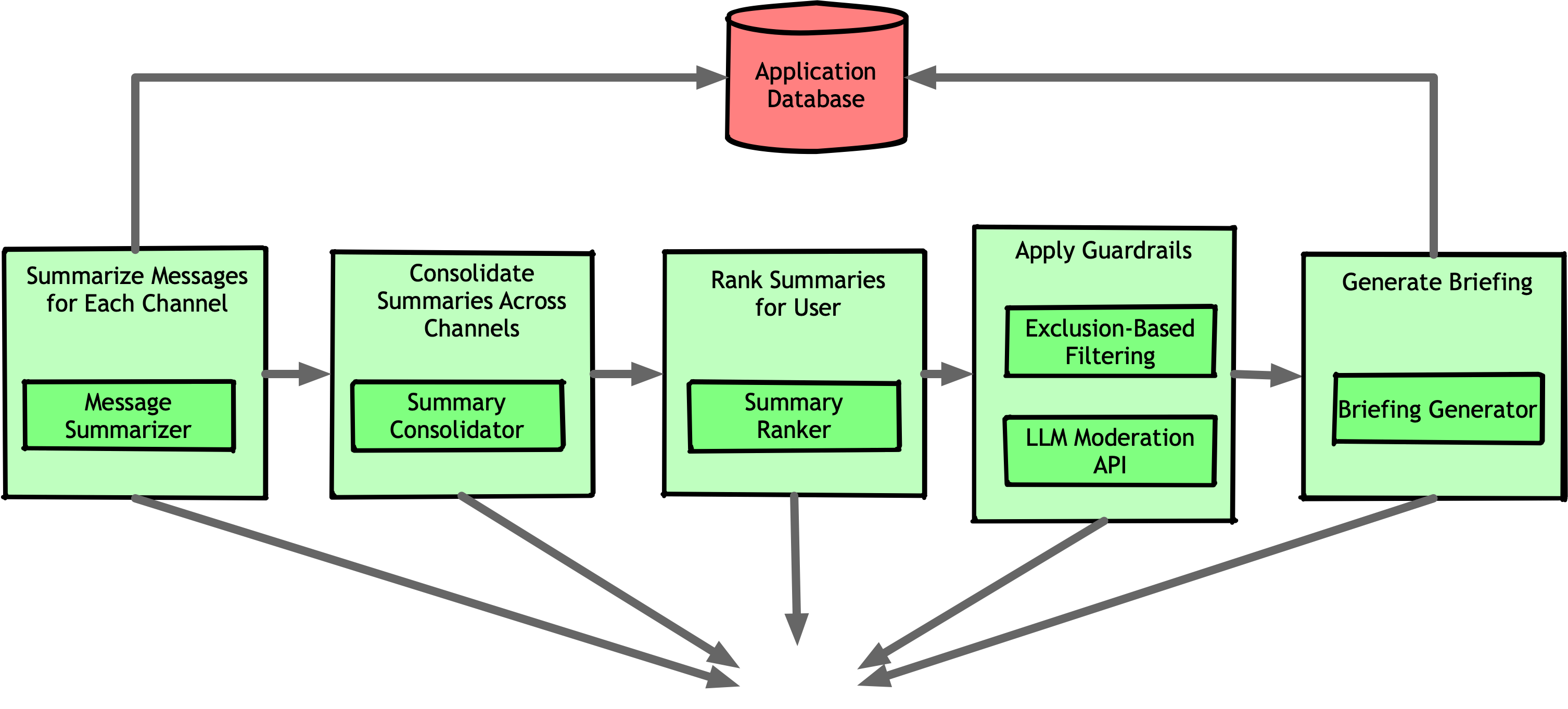
Detailing each step is beyond the scope of this article. In short, we independently arrived at techniques similar to what are now known as Corrective Retrieval-Augmented Generation (CRAG) and RAG-Fusion.
Our Monolithic Inheritance
Before diving into how our approach to inference pipelines evolved, I want to take a step back and look at why AI engineering ended up the way it is.
Much of what we know about building Generative AI applications comes from earlier data science practices. Many of yesterday’s data scientists have rebranded as today’s AI engineers, and modern AI systems still rely on many of the same tools and methodologies as traditional ML. Along with that, we’ve inherited the same well-documented problems that have plagued data pipelines for decades—monolithic, single-use artifacts that experts like Zhamak Dehghani and Danilo Sato have extensively discussed:

Their proposed solution is Data Mesh, a distributed data architecture rooted in classic software engineering principles like Domain-Driven Design. Instead of large, single-purpose pipelines that shuttle data between lakes, databases, and applications, it promotes smaller, self-contained data products that are discoverable, reusable, and composable, enabling more scalable and maintainable data workflows.
Unfortunately, despite the hype around Data Mesh, most data teams haven’t adopted it. They still build monolithic, one-off pipelines, riddled with tech debt and brittle integrations, making data hard to find and needlessly duplicated. This is the world where today’s AI engineers learned to build pipelines—back when they still called themselves data scientists.
As frustrating as this has always been in data science and analytics, the pain was manageable because these teams typically worked on supporting systems—spam classification, content recommendations, or analytics—where failures had fallback strategies and didn’t directly affect core product functionality.
But now, AI is in the critical path of our applications. Technical debt in data pipelines doesn’t just slow things down—it directly impacts product quality, user experience, and business value. If AI is the product, it has to be built with the same rigor as any other mission-critical system.
Introducing Click-to-Context
Back to our product, after the success of the daily briefing, we rushed to launch our second feature: click-to-context. We added a button in Slack that let users right-click any message to get an explainer tailored to its context. This way, they could quickly catch up on conversations after returning from a meeting to a wall of unread messages.
Here’s a video of what it looked like:
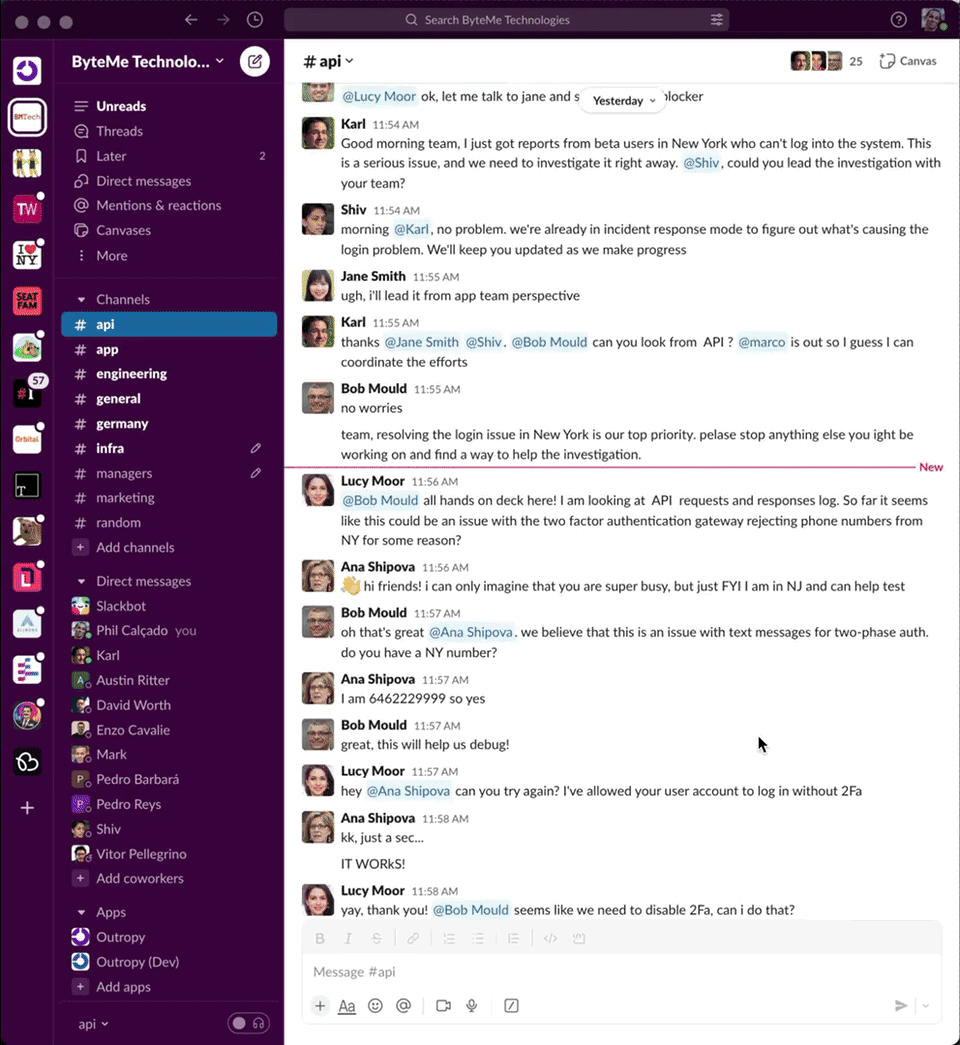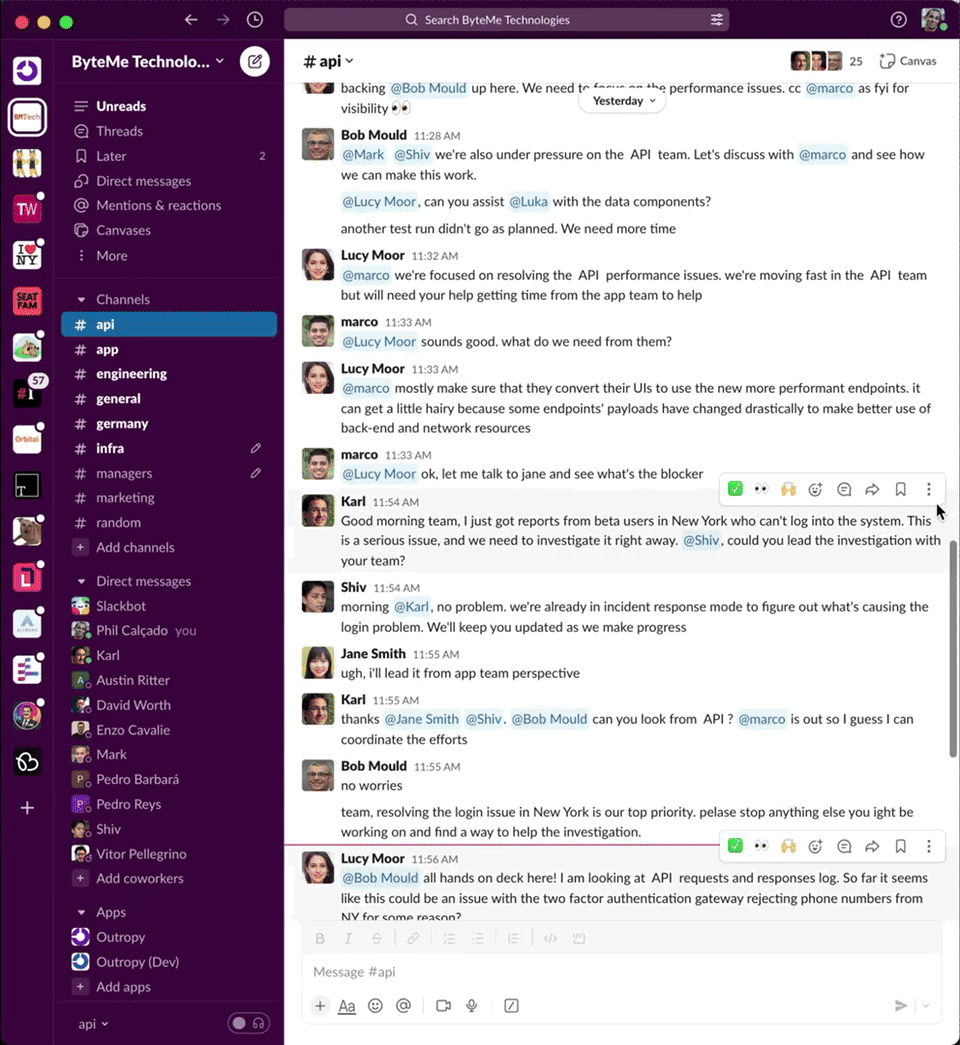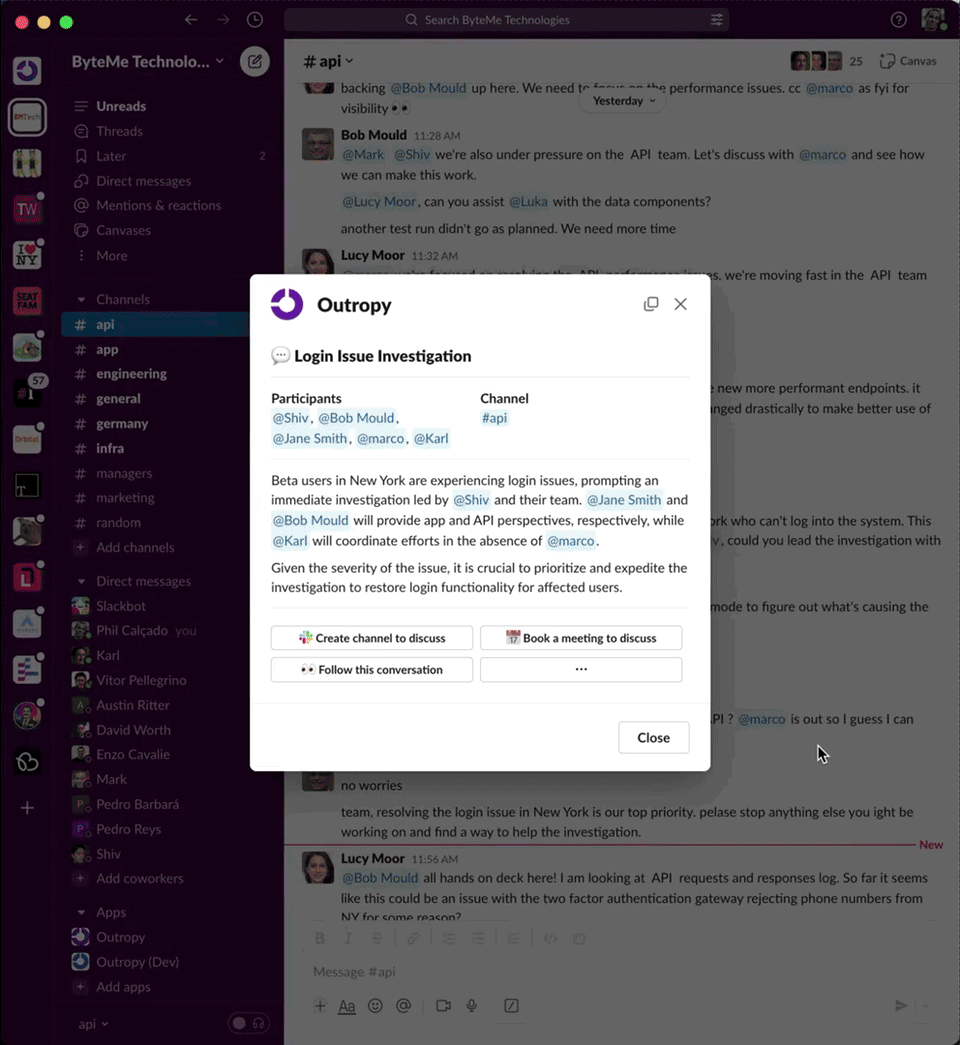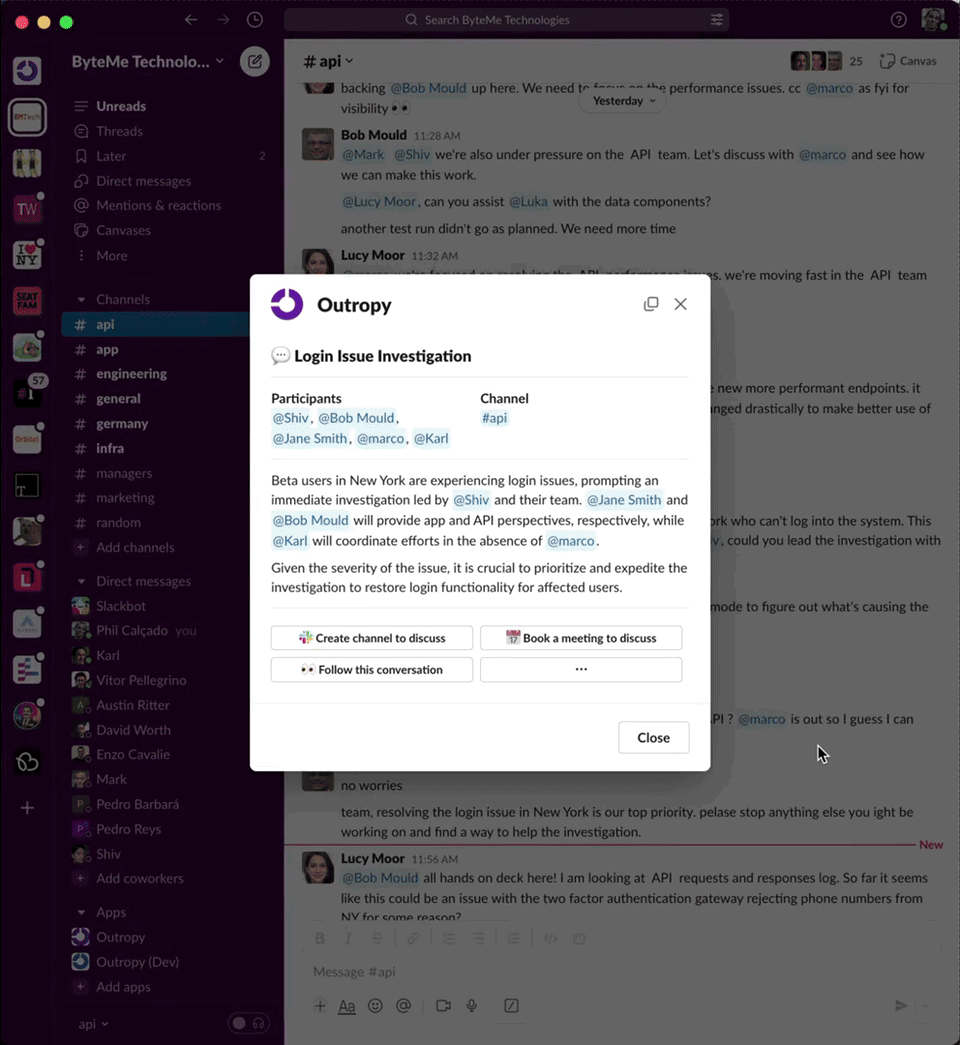
People loved the new feature, and we were adding hundreds of new users every week. One of the coolest moments was discovering an emergent use case in our telemetry: teams working in multiple languages found click-to-context invaluable. Rather than translating messages individually, they could instantly understand the overall conversation.
The logic was very similar to the daily briefing pipeline. The key difference was that instead of pulling messages from multiple channels over a set time frame, it only retrieved messages from the same channel. The selection logic was simple: fetch every message sent within one hour of the right-clicked message.
Behind the scenes, we had to make trade-offs to launch quickly, prioritizing speed over long-term maintainability.
From Monolith to Copypasta
When we started working on Click-to-Context, our application code called our pipeline like this:
To build the new feature, we reused the core logic from the latter half of the daily briefing pipeline and simply added a few components to handle different inputs:
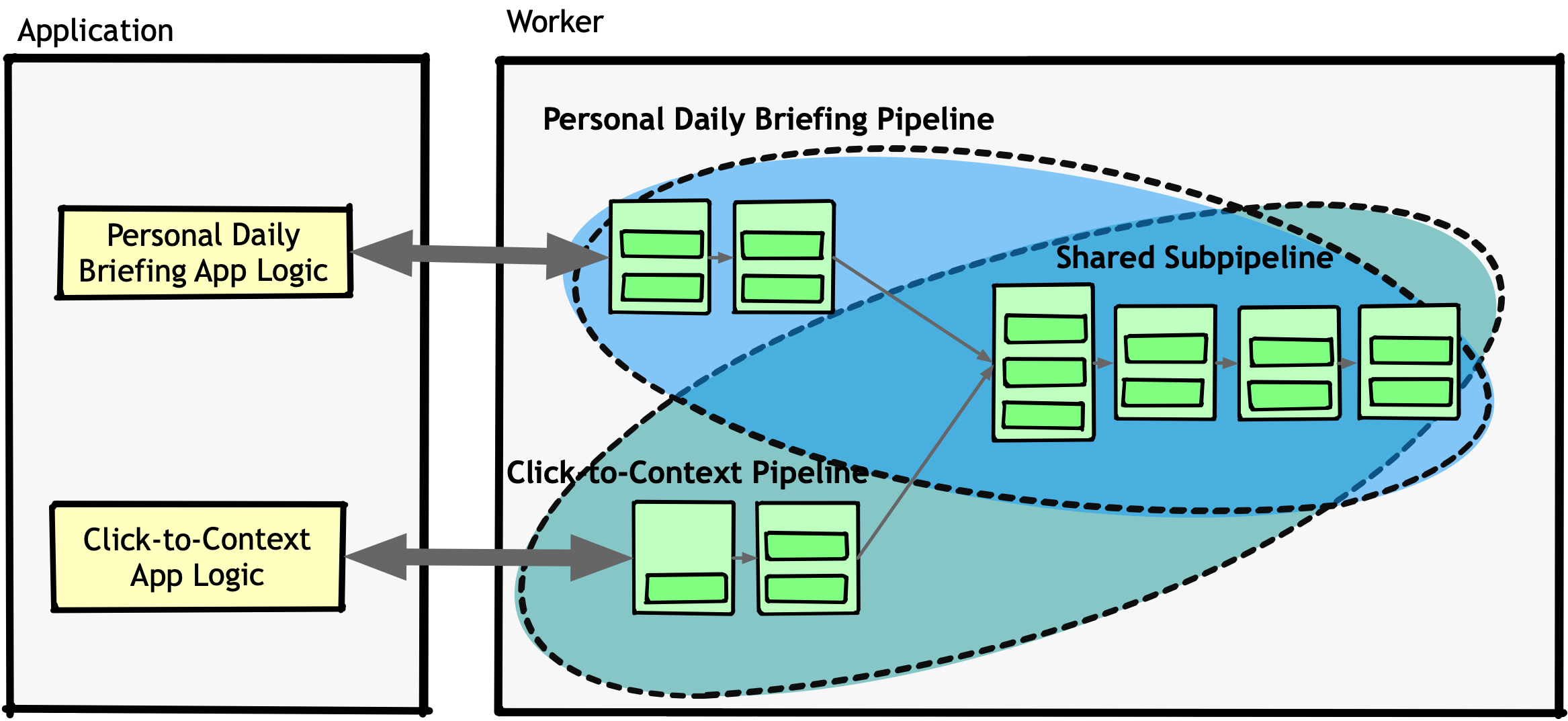
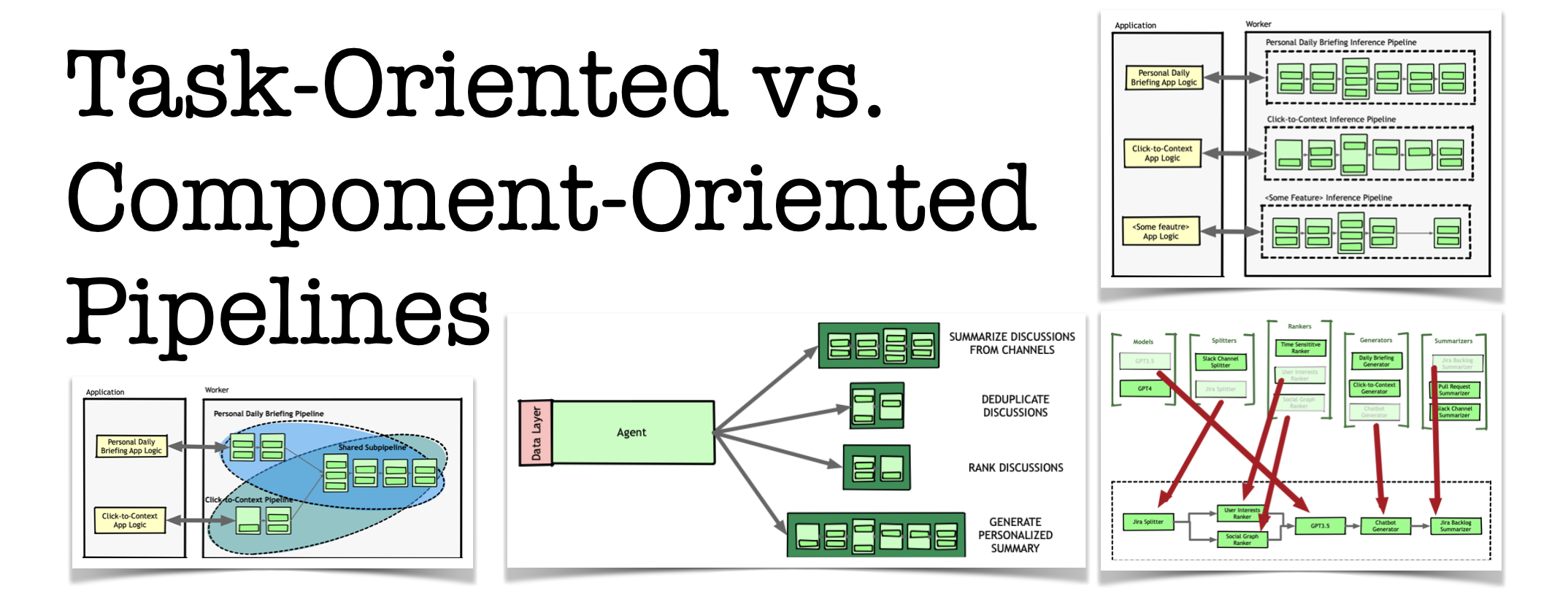
I added shaded regions in the diagram above to highlight an important detail: there was no real encapsulation. The only difference between these pipelines was the entry point, but they shared the same components.
This is where things got complicated. While the daily briefing and click-to-context pipelines had a lot in common, they weren’t exactly the same. The prompts, instructions, and few-shot examples we built for the daily briefing were designed to handle multiple discussions at once, while click-to-context needed to focus on a single discussion and filter out unrelated messages.
To ship the feature quickly, we added context-aware branching inside our components. Each function checked which feature it was serving (via a Context object, similar to Go’s approach, containing metadata like the invoking user, feature type, etc.), then branched into the appropriate logic. This was a nasty hack. Before long, we found ourselves in an increasingly tangled mess of if-else statements, a classic case of control coupling.
There was no time for a proper fix, so we made a trade-off: copy-pasting code for each new pipeline to avoid untangling the logic immediately. Eventually, we ended up with this:
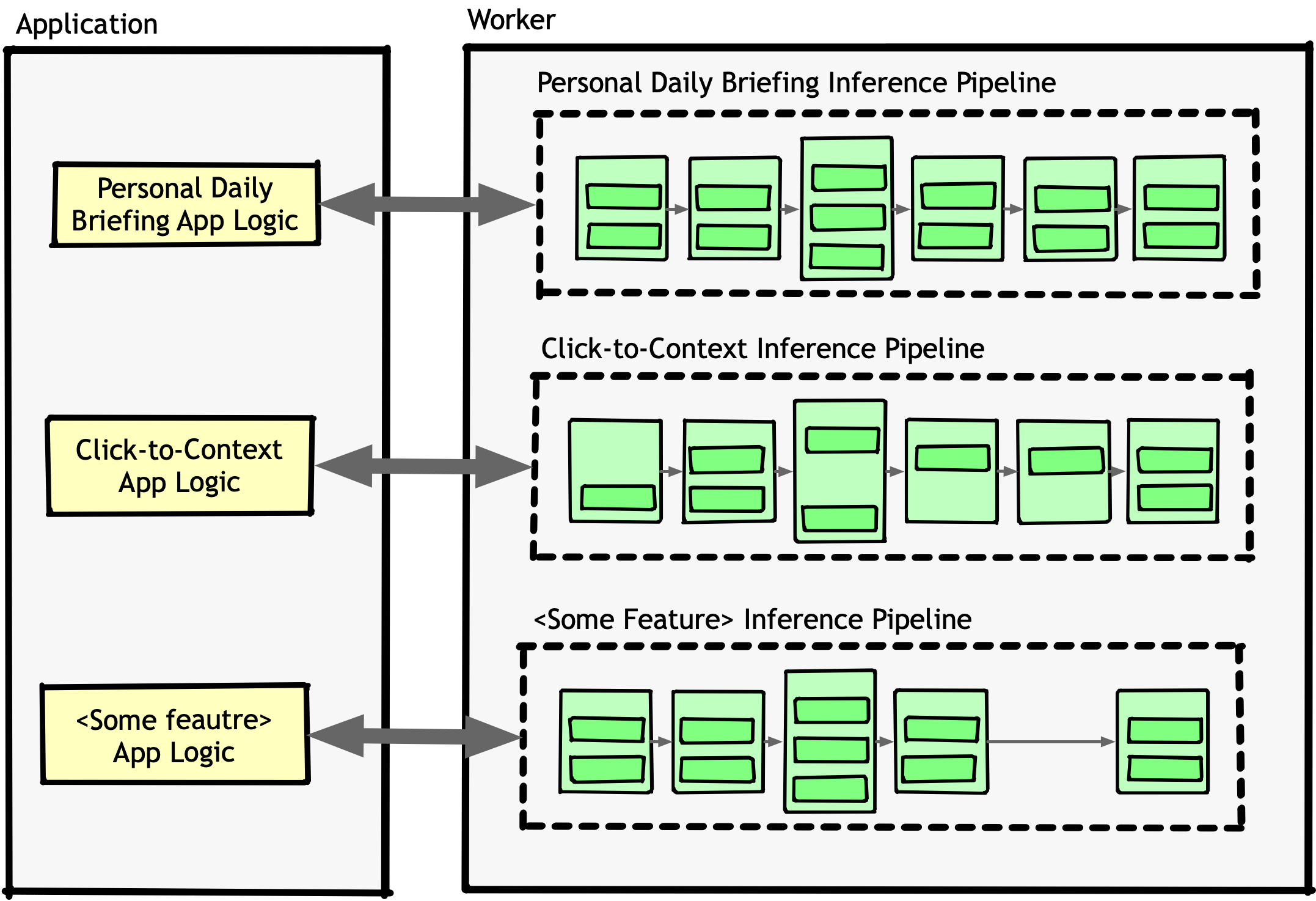
We knew we were taking on tech debt to move fast, but it piled up much faster than expected. Maintaining it was painful. Slightly different versions of the same hundred-line methods were scattered everywhere. Even small changes, like switching from OpenAI’s APIs to Azure’s, turned into multi-week exercises in find-and-replace.
The good news was that we were much more comfortable with the concepts, tools, and techniques of building AI by this point. We were ready to start making our architecture more sustainable. But this raised the real question: what does good architecture even look like for a Generative AI system?
Component-Oriented Design
Our first attempt at bringing order to our pipelines was to clean up the copy-and-paste madness and consolidate duplicated code into reusable components with well-defined interfaces. One major issue became obvious: our components were mixing concerns.
A component that fetched Slack messages also calculated social proximity scores based on interaction frequency, reaction counts, and direct message volume. We split these into a pure data-fetching service and a separate ranking algorithm. This separation made our components more reusable, reduced unexpected dependencies, and lowered the risk of cascading failures when making changes.
With this shift, we started treating our pipelines as assemblies of modular components rather than static workflows.
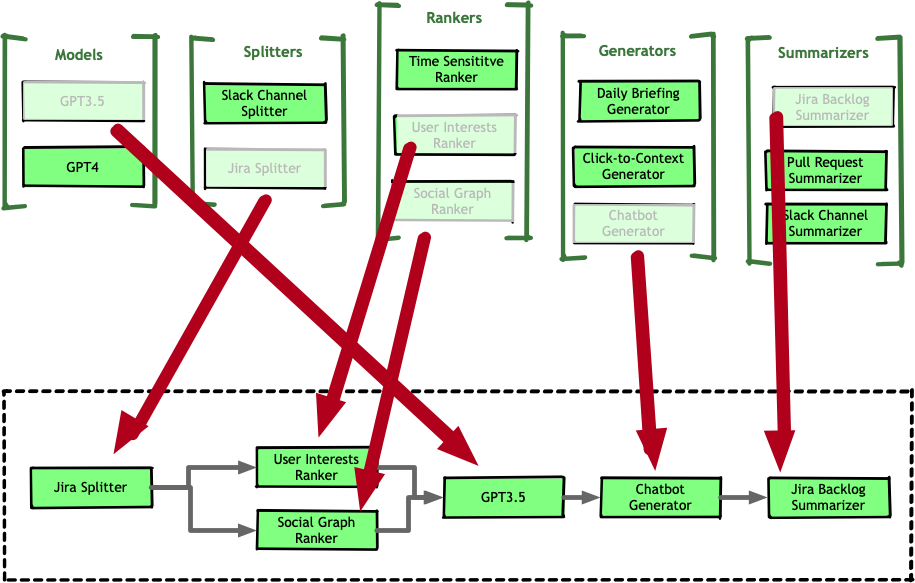
This approach improved code organization, testability, and reusability. Now, instead of rewriting logic for each new pipeline, we could assemble workflows from existing, well-scoped building blocks.
But the core problem remained—we had solved mixed responsibilities at the component level, yet our pipelines themselves were still tangled with multiple concerns. Each pipeline had to orchestrate:
- Data retrieval from different sources (GitHub, Google Calendar, Slack)
- Error handling and API inconsistencies
- Processing logic (summarization, ranking, filtering)
- Context-aware adaptations (personalization, deduplication, formatting)
The problem wasn’t just messy internals—it was structural. Pipelines weren’t truly independent; they still carried hardcoded assumptions about data shape, execution order, and failure modes. The complexity had just moved up a level.
This is exactly how frameworks like LangChain and LlamaIndex operate today—frameworks we never used but independently arrived at similar patterns. Their main benefit is providing pre-built conveniences that speed up implementation, allowing engineers to assemble pipelines by chaining components together. But they do little to solve the real challenges of inference pipeline design. This bottom-up approach ultimately produces brittle, single-purpose pipelines that don’t scale beyond their initial use case.
Introducing Companion
The Component-based approach above was our main approach through our beta launch in September 2023 and hit 10,000 users. Adding new features was our focus, not iterating over old ones. So, once a pipeline was in place, we rarely revisited it.
After a year of vaporware announcements, Salesforce finally released Slack AI in February 2024. While its features were basic compared to ours, its sheer market presence made one thing clear: we couldn’t remain a Slack-only tool.
That’s when we launched Companion, our always-present Google Chrome extension. It offered many of the same features as our Slack integrations—Click-to-Context now worked everywhere as you select some text in any web page and click the Outropy button to bring up context—and a lot of new additional capabilities, like bringing context based on whatever was displayed on your screen and helping with meeting preparation and, the most favorite feature of all time, calendar refactoring.
On the engineering side, Companion wasn’t just a UI change—it forced us to rethink how our inference pipelines worked. Moving from request/response interactions in Slack to a persistent, agentic system meant refactoring our pipelines into reusable, object-like agents. Once we had that foundation, we could start designing the next generation of inference pipelines.
Task-Oriented Design
Software engineering is about breaking big, unsolvable problems into smaller, solvable ones, where each piece contributes to solving the larger issue. Instead of tackling complex, tangled problems with equally tangled pipelines, we needed a different approach: decomposing inference into smaller, meaningful units.
In his seminal book Working Effectively with Legacy Code, Michael Feathers introduces the concept of a seam:
A place where you can vary behavior in a software system without editing in that place. For instance, a call to a polymorphic function on an object is a seam because you can subclass the class of the object and have it behave differently.
A seam is ultimately a leverage point in an architecture. To scale, we needed to identify and exploit the seams in ours.
Our breakthrough came when we stopped thinking bottom-up and instead mapped our pipelines from the top down. Looking at an example pipeline we discussed earlier:
- Summarize Discussions in Each Channel
- Identify the Slack channels each user belongs to.
- For each channel, summarize all discussions from the last 24 hours.
- Identify which topics each discussion belongs to.
- Consolidate Summaries Across Channels
- Send the list of all discussed topics to ChatGPT.
- Ask it to consolidate and deduplicate similar topics.
- Rank Summaries for the User
- Fetch the list of topics the user currently cares about.
- Send this list with consolidated summaries to ChatGPT.
- Ask it to choose the three most relevant summaries based on user preferences.
- Generate a Personalized Summary
- Take the three selected summaries and user-specific information.
- Ask ChatGPT to generate a briefing tailored to the user’s perspective.
We were immediately drawn to these big verbs—Summarize, Consolidate, Rank, Generate. These weren’t just individual steps in a single workflow—they were standalone, reusable tasks. Everything else was just implementation detail.
Instead of treating pipelines as rigid, single-purpose workflows, we recognized an opportunity: break these tasks into separate, self-contained pipelines that could be composed and reused across different workflows.
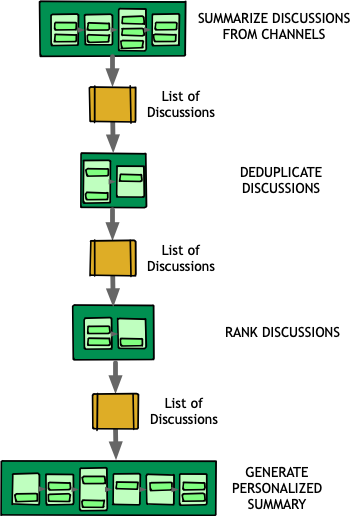
Unlike component-oriented pipelines, where stages within a pipeline directly depend on each other, these task-oriented pipelines are self-contained. Each one takes a specific input, produces a specific output, and makes no assumptions about where the input comes from or how the output will be used.
This was key: by decoupling these tasks, we not only improved maintainability but also unlocked reuse across multiple AI workflows. A pipeline that summarized discussions from Slack could just as easily summarize discussions from GitHub code reviews or comments on Google Docs—without modification.
In fact, this diagram oversimplifies things. If you recall our system architecture from Part I, inference pipelines weren’t standalone—they were part of agents.
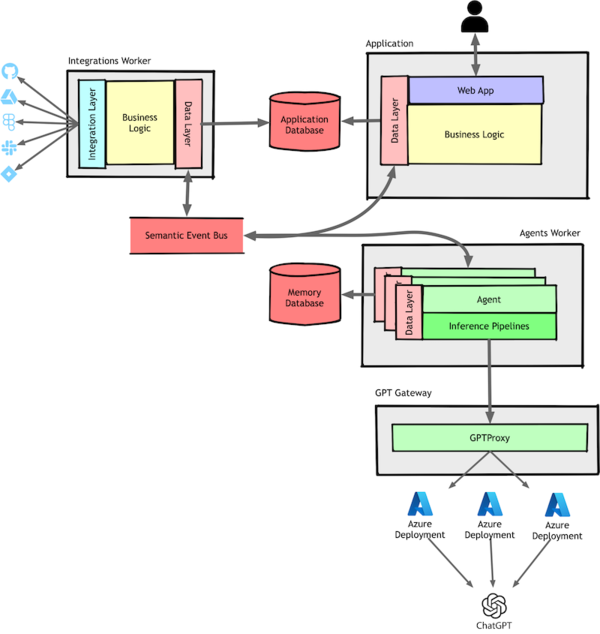
This means that instead of pipelines calling each other directly, agents orchestrated the process, chaining together small inference pipelines dynamically to accomplish a goal.
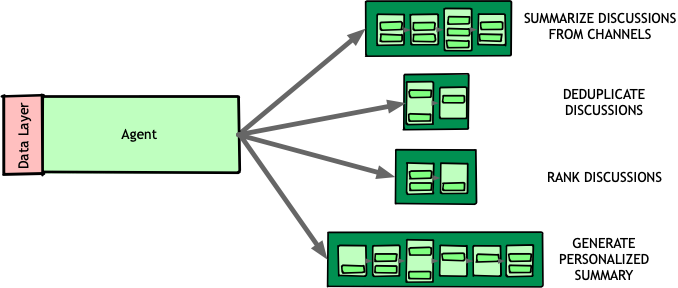
With this shift, task-oriented pipelines became the foundation of our AI system. By focusing on what each stage of inference needed to accomplish rather than how it was implemented, we built a system that was modular, composable, and adaptable to new workflows.
We used the task-oriented approach for the entire life of our product, and it worked so well that tasks became the main unit of abstraction developers use when building systems on the Outropy platform.
Building Pipelines
Breaking inference down into task-oriented pipelines gave us a modular, composable system, but translating these concepts into working code was another challenge entirely.
Don’t let the neat diagrams fool you. The first version of this pipeline was a beast—15,000 lines of Python crammed into a single file, with code snippets bouncing between Jupyter Notebooks, where we initially built and tested everything.
But as we refactored our code into something more structured, we realized that AI systems inherit all the usual maintenance headaches of traditional software—slowing development, making systems harder to debug, and introducing risks around security, latency, and resilience. On top of that, they add their own unique pains.
Beyond their sensitivity to input format, AI pipelines require constant retries when results aren’t acceptable. Even minor input changes can cascade into unpredictable behavior. Keeping things working as expected meant continually adjusting pipelines, even after they were deployed.
That led us to one of the most important lessons we learned: AI product development is mostly trial and error. If your architecture slows down daily iterations, it doesn’t just make engineering harder—it directly impacts product quality and user experience.
So while the changes we made—both here and in Part I—helped us build more maintainable, production-ready pipelines, we still needed a way to experiment and iterate quickly, even while the system was in production.
After evaluating several solutions, we chose Temporal to implement durable workflows. At its core, Temporal is built around a simple but powerful idea: separate the parts of your system that handle business logic from those that perform side effects. This distinction is straightforward, especially for engineers familiar with Functional Programming principles.
In Temporal, workflows handle business logic and are idempotent, meaning they always produce the same result, even if retried. But workflows can’t perform side effects—they can’t call OpenAI’s API or write to a database. Instead, they invoke activities, which are isolated at both the code and runtime levels.
This separation lets Temporal manage retries, timeouts, and failures automatically. If an activity fails—say, due to network issues—Temporal handles the retry logic, so we didn’t have to build it ourselves.
Think of Temporal as a finer-grained Service Mesh, but for workflows inside your application rather than independent services.
At first, we modeled each pipeline as a single Temporal workflow.
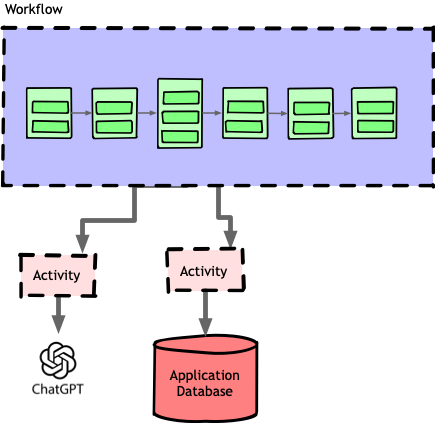
Even as our design evolved, we stuck to this model: a single workflow for the whole pipeline, with each stage and substage implemented as plain Python objects added through a basic dependency injection system we hacked together.
As we started adopting the task-oriented approach discussed above, it no longer made sense to have a single workflow for the entire pipeline. The natural next step was to give each task pipeline its own Temporal workflow.
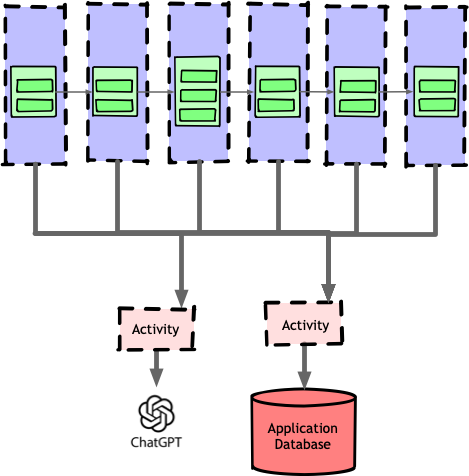
This improved modularity but introduced a new problem: Temporal’s benefits were now isolated to individual pipelines. Communication between pipelines still relied on external coordination, losing Temporal’s built-in reliability when chaining task workflows together.
Since agents were already responsible for coordinating pipelines, the best solution was to make the agent itself a Temporal workflow. The agent would then call each task pipeline as a subworkflow, allowing Temporal to manage everything as a single transaction.
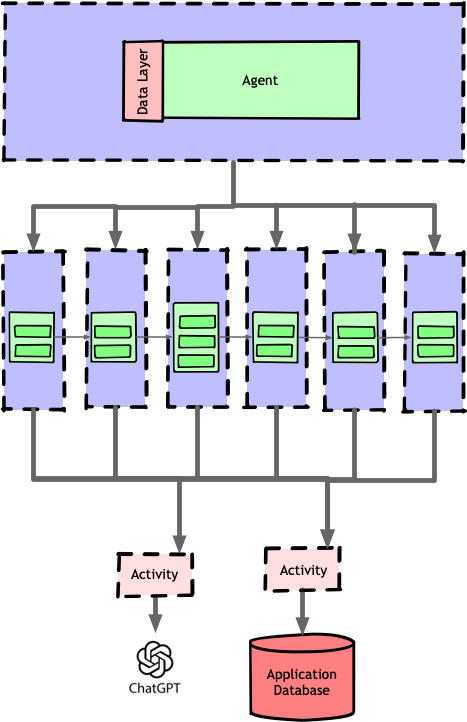
This design also let the agent workflow act as a supervisor, tracking the state of the entire inference pipeline and handling errors that weren’t automatically resolved by Temporal. The result was a fully managed execution flow that not only recovered from failures but allowed us to iterate rapidly on individual tasks without disrupting the whole system—crucial for maintaining the quality of our AI experiences.
This architecture proved robust enough to support our evolving product needs, including the shift from Slack-only interactions to the more proactive, context-aware Companion experience. In the final article of this series, we’ll break down how we built our agents, got them to coordinate without stepping on each other’s toes, and kept them from spiraling into unpredictable behavior.
Comments
This post has a thread on Bluesky. Like, repost, or reply there and it will show up below.
Replies