Building AI Products—Part I: Back-end Architecture
In 2023, we launched an AI-powered Chief of Staff for engineering leaders—an assistant that unified information across team tools and tracked critical project developments. Within a year, we attracted 10,000 users, outperforming even deep-pocketed incumbents such as Salesforce and Slack AI. Here is an early demo:
By May 2024, we realized something interesting: while our AI assistant was gaining traction, there was overwhelming demand for the technology we built to power it. Engineering leaders using the platform were reaching out non-stop to ask not about the tool but how we made our agents work so reliably at scale and be, you know, actually useful. This led us to pivot to Outropy, a developer platform that enables software engineers to build AI products.
Building with Generative AI at breakneck pace while the industry was finding its footing taught us invaluable lessons—lessons that now form the core of the Outropy platform. While LinkedIn overflows with thought leaders declaring every new research paper a “game changer,” few explain what the game actually is. This series aims to change that.
This three-part series will cover:
- How we built the AI agents powering the assistant
- How we constructed and operate our inference pipelines
- The AI-specific tools and techniques that made it all work
This order is intentional. So much content out there fixates on choosing the best reranker or chasing the latest shiny technology, and few discuss how to build useful AI software. This is a report from the trenches, not the ivory tower.
Structuring an AI Application
Working with AI presents exciting opportunities and unique frustrations for a team like ours, with decades of experience building applications and infrastructure.
AI’s stochastic (probabilistic) nature fundamentally differs from traditional deterministic software development—but that’s only part of the story. With years of experience handling distributed systems and their inherent uncertainties, we’re no strangers to unreliable components.
The biggest open questions lie in structuring GenAI systems for long-term evolution and operation, moving beyond the quick-and-dirty prompt chaining that suffices for flashy demos.
In my experience, there are two major types of components in a GenAI system:
- Inference Pipelines: A deterministic sequence of operations that transforms inputs through one or more AI models to produce a specific output. Think of RAG pipelines generating answers from documents—each step follows a fixed path despite the AI’s probabilistic nature.
- Agents: Autonomous software entities that maintain state while orchestrating AI models and tools to accomplish complex tasks. These agents can reason about their progress and adjust their approach across multiple steps, making them suitable for longer-running operations.
Our journey began with a simple Slack bot. This focused approach let us explore GenAI’s possibilities and iterate quickly without getting bogged down in architectural decisions. During this period, we only used distinct inference pipelines and tied their results together manually.
This approach served us well until we expanded our integrations and features. As the application grew, our inference pipelines became increasingly complex and brittle, struggling to reconcile data from different sources and formats while maintaining coherent semantics.
This complexity drove us to adopt a multi-agentic system.
What are agents, really?
The industry has poured billions into AI agents, yet most discussions focus narrowly on RPA-style, no-code and low-code automation tools. Yes, frameworks like CrewAI, AutoGen, Microsoft Copilot Studio, and Salesforce’s Agentforce serve an important purpose—they give business users the same power that shell scripts give Linux admins. But just like you wouldn’t build a production system in Bash, these frameworks are just scratching the surface of what agents can be.
The broader concept of agents has a rich history in academia and AI research, offering much more interesting possibilities for product development. Still, as a tiny startup on a tight deadline, rather than get lost in theoretical debates, we distilled practical traits that guided our implementation:
- Semi-autonomous: Functions independently with minimal supervision, making local decisions within defined boundaries.
- Specialized: Masters specific tasks or domains rather than attempting general-purpose intelligence.
- Reactive: Responds intelligently to requests and environmental changes, maintaining situational awareness.
- Memory-driven: Maintains and leverages both immediate context and historical information to inform decisions.
- Decision-making: Analyzes situations, evaluates options, and executes actions aligned with objectives.
- Tool-using: Effectively employs various tools, systems, and APIs to accomplish tasks.
- Goal-oriented: Adapts behavior and strategies to achieve defined objectives while maintaining focus.
While these intelligent components are powerful, we quickly learned that not everything needs to be an agent. Could we have built our Slackbot and productivity tool connectors using agents? Sure, but the traditional design patterns worked perfectly well, and our limited resources were better spent elsewhere. The same logic applied to standard business operations—user management, billing, permissions, and other commodity functions worked better with conventional architectures.
This meant that we had the following layered architecture inside our application:
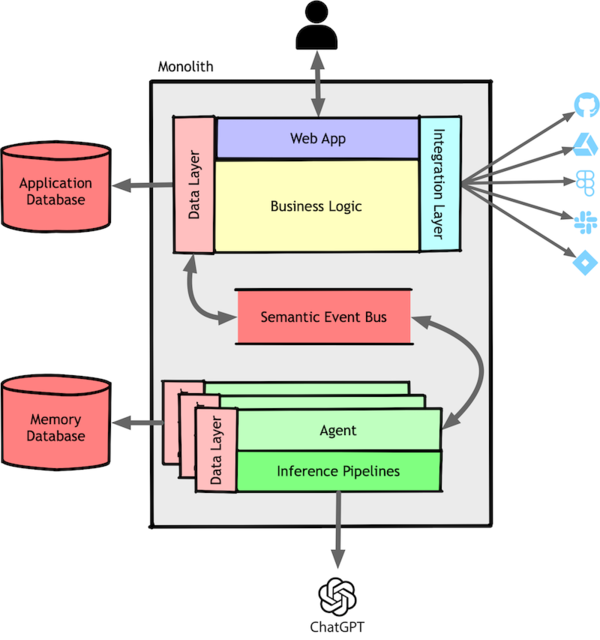
Agents are not Microservices
I’ve spent the last decade deep in microservices—from pioneering work at ThoughtWorks to helping underdogs like SoundCloud, DigitalOcean, SeatGeek, and Meetup punch above their weight. So naturally, that’s where we started with our agent architecture.
Initially, we implemented agents as a service layer with traditional request/response cycles:
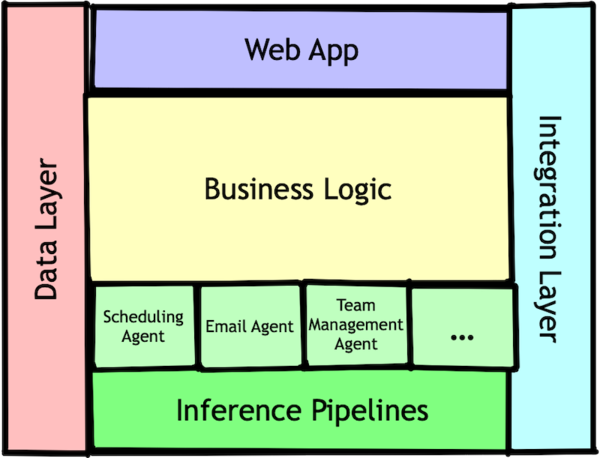
One of the biggest appeals of this architecture was that, even if we expected our application to be a monolith for a long time, it creates an easier path to extracting services as needed and benefit from horizontal scalability when the time comes.
Unfortunately, the more we went down the path, the more obvious it became that stateless microservices and AI agents just don’t play nice together. Microservices are all about splitting a particular feature into small units of work that need minimal context to perform the task at hand. The same traits that make agents powerful create a significant impedance mismatch with these expectations:
- Stateful Operation: Agents must maintain rich context across interactions, including conversation history and planning states. This fundamentally conflicts with microservices’ stateless nature and complicates scaling and failover.
- Non-deterministic Behavior: Unlike traditional services, agents are basically state machines with unbounded states. They behave completely differently depending on context and various probabilistic responses. This breaks core assumptions about caching, testing, and debugging.
- Data-Intensive with Poor Locality: Agents process massive amounts of data through language models and embeddings, with poor data locality. This contradicts microservices’ efficiency principle.
- Unreliable External Dependencies: Heavy reliance on external APIs such as LLMs, embedding services, and tool endpoints creates complex dependency chains with unpredictable latency, reliability, and costs.
- Implementation Complexity: The combination of prompt engineering, planning algorithms, and tool integrations creates debugging challenges that compound with distribution.
Not only did this impedance mismatch cause a lot of pain while writing and maintaining the code, but agentic systems are so far away from the ubiquitous 12-factor model that attempting to leverage existing microservice tooling became an exercise in fitting square pegs into round holes.
Agents are more like objects
If microservices weren’t the right fit, another classic software engineering paradigm offered a more natural abstraction for agents: object-oriented programming.
Agents naturally align with OOP principles: they maintain encapsulated state (their memory), expose methods (their tools and decision-making capabilities via inference pipelines), and communicate through message passing. This mirrors Alan Kay’s original vision:
OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things.
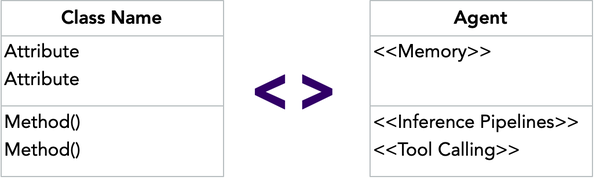
We’ve been in the industry long enough to remember the nightmares of distributed objects and the fever dreams of CORBA and J2EE. Yet, objects offered us a pragmatic way to quickly iterate on our product and defer the scalability question until we actually need to solve that.
We evolved our agents from stateless Services to Entities, giving them distinct identities and lifecycles. This meant each user or organization maintained their own persistent agent instances, managed through Repositories in our database.
This drastically simplified our function signatures by eliminating the need to pass extensive context as arguments on every agent call. It also lets us leverage battle-tested tools like SQLAlchemy and Pydantic to build our agents, while enabling unit tests with stubs/mocks instead of complicated integration tests.
Implementing Agentic Memory
Agents’ memories can be as simple as a single value to as complicated as keeping track of historical information since the beginning of times. In our assistant, we have both types and more.
For simple, narrow-focused agents such as the “Today’s Priorities” agents had to remember nothing more than a list of high-priority things they were monitoring and eventually taking action, such as sending a notification if they weren’t happy with the progress. Others, like our “Org Chart Keeper” had to keep track of all interactions between everyone in the organizations and use that to infer reporting lines and teams people belonged to.
The agents with simpler persistence needs would usually just store their data on a dedicated table using SQLAlchemy’s ORM. This obviously wasn’t an option for the more complicated memory needs, so we had to apply a different model
After some experimentation, we adopted CQRS with Event Sourcing. In essence, every state change—whether creating a meeting or updating team members—was represented as a Command, a discrete event recorded chronologically—much like a database transaction log. The current state of any object could then be reconstructed by replaying all its associated events in sequence.
While this approach has clear benefits, replaying events solely to respond to a query is slow and cumbersome, especially when most queries focus on the current state rather than historical data. To address, CQRS suggests that we maintain a continuously updated, query-optimized representation of the data, similar to materialized views in a relational database. This ensured quick reads without sacrificing the advantages of event sourcing. We started off storing events and query models in Postgres, planning to move them to DynamoDB when we started having issues.
One big challenge in this model is that only an agent knows what matters to them. For example, if a user would change cancel a scheduled meeting, which agents should care about this event? The scheduling agent for sure, but if this meeting was about a specific project you might also want the project management agent to know about it as it might impact the roadmap.
Rather than building an all-knowing router to dispatch events to the right agents—risking the creation of a God object—we took inspiration from my experience at SoundCloud. There, we developed a semantic event bus enabling interested parties to publish and observe events for relevant entities:
Soon enough, we realized that there was a big problem with this model; as our microservices needed to react to user activity. The push-notifications system, for example, needed to know whenever a track had received a new comment so that it could inform the artist about it. […] over several iterations we developed a model called Semantic Events, where changes in the domain objects result in a message being dispatched to a broker and consumed by whichever microservice finds the message interesting.
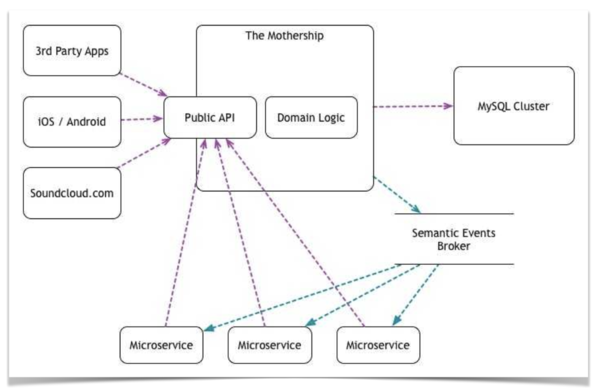
Following this model, all state-change events were posted to an event bus that agents could subscribe to. Each agent filtered out irrelevant events independently, removing the need for external systems to know what they cared about. Since we were working within a single monolith at the time, we implemented a straightforward Observer pattern using SQLAlchemy’s native event system, with plans to eventually migrate to DynamoDB Streams.
Inside our monolith, the architecture looked like this:
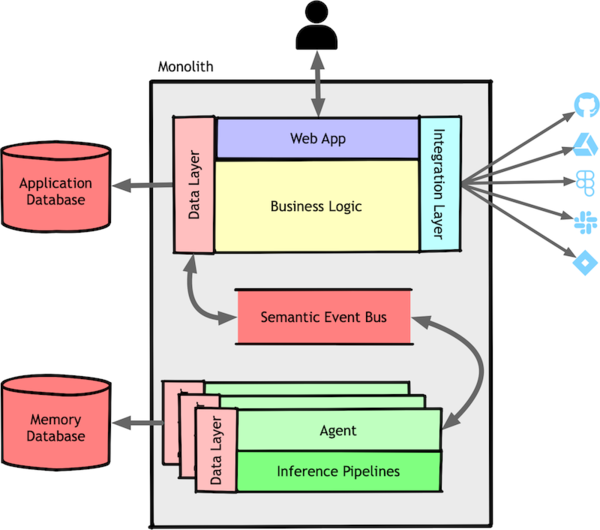
Managing both the ORM approach for simpler objects and CQRS for more complex needs grew increasingly cumbersome. Small refactorings or shared logic across all agents became harder than necessary. Ultimately, we decided the simplicity of ORM wasn’t worth the complexity of handling two separate persistence models. We converted all agents to the CQRS style but retained ORM for non-agentic components.
Handling Events in Natural Language
CQRS and its supporting tools excel with well-defined data structures. At SoundCloud, events like UploadTrack or CreateTrackComment were straightforward and unambiguous. AI systems, however, present a very different challenge.
Most AI systems deal with the uncertainty of natural language. This makes the process of consolidating the Commands into a “materialized view” hard. For example, what events correspond to someone posting a Slack message like “I am feeling sick and can’t come to the office tomorrow, can we reschedule the project meeting?”
We started with the naive approach most agentic systems use: running every message through an inference pipeline to extract context, make decisions, and take actions via tool calling. This approach faced two problems: first, reliably doing all this work in a single pipeline is hard even with frontier models—more on this in part II. Second, we ran into the God object problem discussed earlier—our logic was spread across many agents, and no single pipeline could handle everything.
One option involved sending each piece of content—Slack messages, GitHub reviews, Google Doc comments, emails, calendar event descriptions…—to every agent for processing. While this was straightforward to implement via our event bus, each agent would need to run its inference pipeline for every piece of content. This would offer all sorts of performance and cost issues due to frequent calls to LLMs and other models, especially considering that the vast majority of content wouldn’t be relevant to a particular agent.
We wrestled with this problem for a while, exploring some initially promising but ultimately unsuccessful attempts at Feature Extraction using simpler ML models instead of LLMs. That said, I believe this approach can work well in constrained domains—indeed, we use it in Outropy to route requests within the platform.
Our solution built on Tong Chen’s Proposition-Based Retrieval research. We already used this approach to ingest structured content like CSV files, where instead of directly embedding it into a vector database, we first use an LLM to generate natural language factoids about the content. While these factoids add no new information, their natural language format makes vector similarity search much more effective than the original spreadsheet-like structure.
Our solution was to use an LLM to generate propositions for every message, structured according to a format inspired by Abstract Meaning Representation, a technique from natural language processing.
This way, if user Bob sends a message like “I am feeling sick and can’t come to the office tomorrow, can we reschedule the project meeting?” on the #project-lavender channel we would get structured propositions such as:
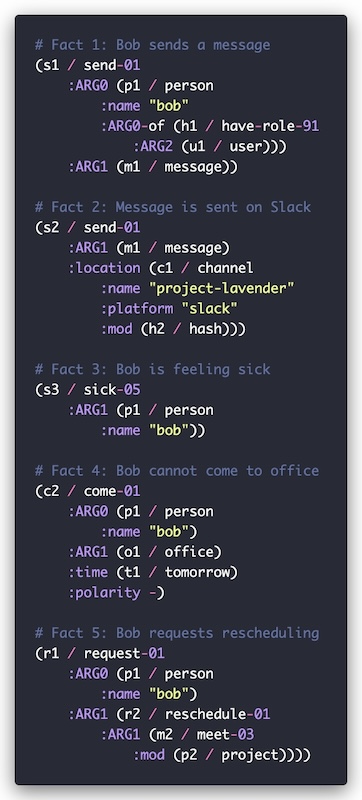
Naturally, we had to carefully batch messages and discussions to minimize costs and latency. This necessity became a major driver behind developing Outropy’s automated pipeline optimization using Reinforcement Learning.
Scaling to 10,000 Users
As mentioned a few times, Throughout this whole process, it was very important to us to minimize the amount of time and energy invested in technical topics unrelated to learning about our users and how to use AI to build products.
We kept our assistant as a single component, with a single code base and a single container image that we deployed using AWS Elastic Container Service. Our agents were simple Python classes using SQLAlchemy and Pydantic, and we relied on FastAPI and asyncio’s excellent features to handle the load. Keeping things simple allowed us to make massive progress on the product side, to a point we went from 8 to 2,000 users in about two months.
That’s when things started breaking down. Our personal daily briefings—our flagship feature—went from taking minutes to hours per user. We’d trained our assistant to learn each user’s login time and generate reports an hour before, ensuring fresh updates. But as we scaled, we had to abandon this personalization and batch process everything at midnight, hoping reports would be ready when users logged in.
As an early startup, growth had to continue, so we needed a quick solution. We implemented organization-based sharding with a simple configuration file: smaller organizations shared a container pool, while those with thousands of users got dedicated resources. This isolation allowed us to keep scaling while maintaining performance across our user base.
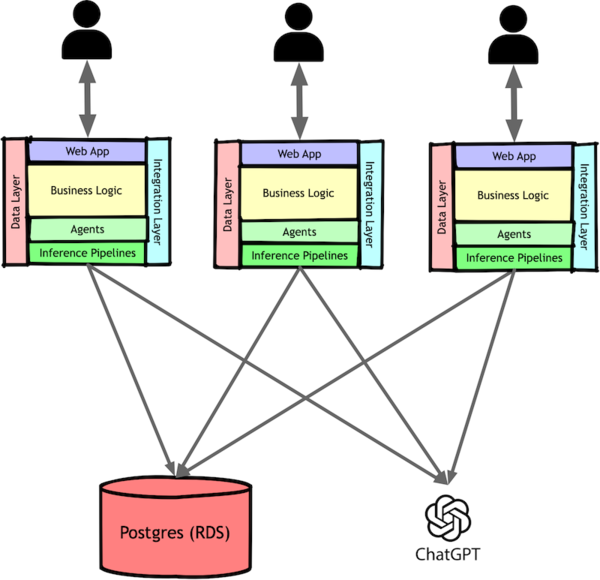
This simple change gave us breathing room by preventing larger accounts from blocking smaller ones. We also added priority processing, deprioritizing inactive users and those we learned were away from work.
While sharding gave us parallelism, we quickly hit the fundamental scaling challenges of GenAI systems. Traditional microservices can scale horizontally because their external API calls are mostly for data operations. But in AI systems, these slow and unpredictable third-party API calls are your critical path. They make the core decisions, and this means everything is blocked until you get a response.
Python’s async features proved invaluable here. We restructured our agent-model interactions using Chain of Responsibility, which let us properly separate CPU-bound and IO-bound work. Combined with some classic systems tuning—increasing container memory and ulimit for more open sockets—we saw our request backlog start to plummet.
OpenAI rate limits became our next bottleneck. We responded with a token budgeting system that applied backpressure while hardening our LLM calls with exponential backoffs, caching, and fallbacks. Moving the heaviest processing to off-peak hours gave us extra breathing room.
Our final optimization on the architectural: moving from OpenAI’s APIs to Azure’s GPT deployments. The key advantage was Azure’s per-deployment quotas, unlike OpenAI’s organization-wide limits. This let us scale by load-balancing across multiple deployments. To manage the shared quota, we extracted our GPT calling code into a dedicated service rather than adding distributed locks
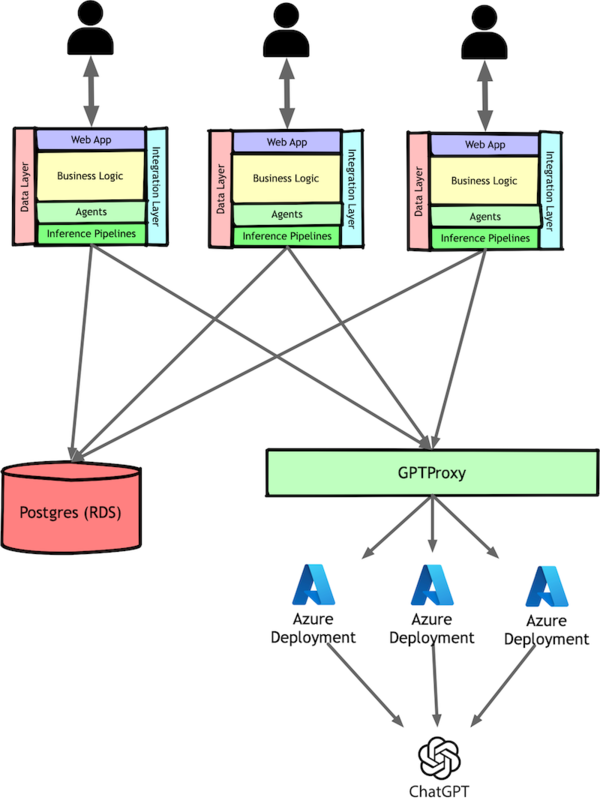
The Zero-one-infinity rule
One of my favorite adages in computer science is “There are only three numbers: zero, one, and infinity.” In software engineering, this manifests as having either zero modules, a monolith, or an arbitrary and always-growing number. As such, extracting the GPTProxy as our first remote service paved the way for similar changes.
The most obvious opportunity to simplify our monolith and squeeze more performance from the system was extracting the logic that pulled data from our users’ connected productivity tools. The extraction was straightforward, except for one challenge: our event bus needed to work across services. We kept using SQLAlchemy’s event system, but replaced our simple observer loop with a proper pub/sub implementation using Postgres as a queue.
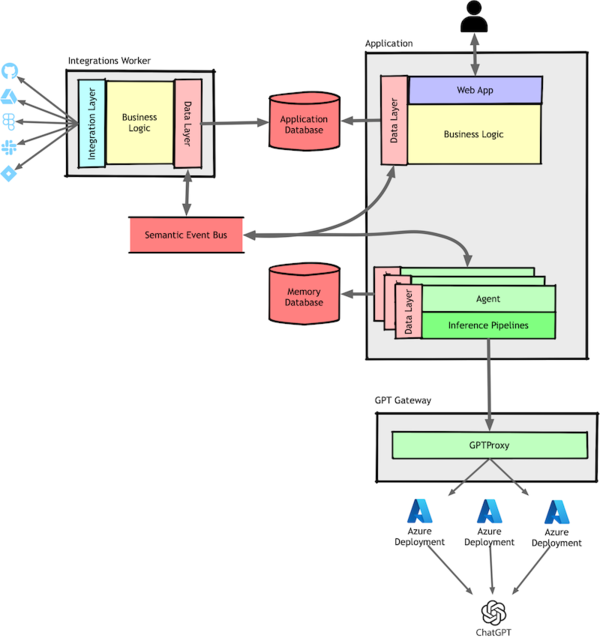
This change dramatically simplified things—we should have done it from the start. It isolated a whole class of errors to a single service, making debugging easier, and let developers run only the components they were working on.
Encouraged by this success, we took the next logical step: extracting our agents and inference pipelines into their own component.
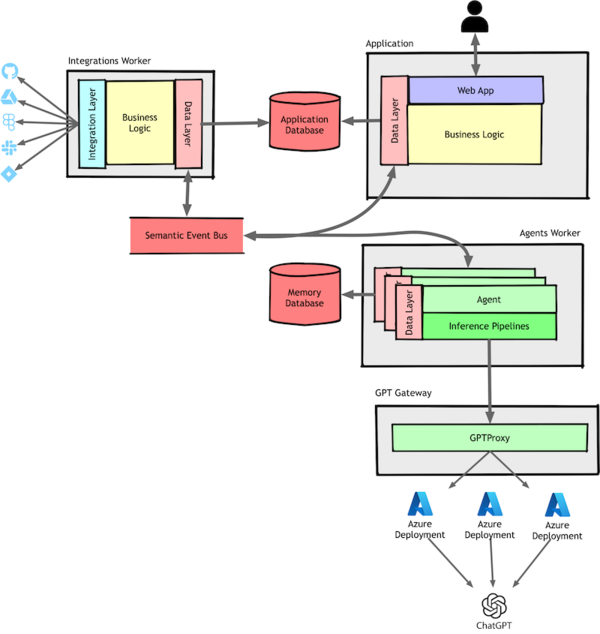
This is where my familiar service extraction playbook stopped working. I’ll cover the details of our inference pipelines in the next article, but first, let’s talk about how we distributed our agents.
Agents as Distributed Objects
As successful as we were with modeling agents as objects, we’d always been wary of distributing them. My ex-colleague Martin Fowler’s First Law of Distributed Objects puts it best: don’t.
Still, I think that Martin’s “exception” for microservices applies just as well for agents:
[My objection is that] although you can encapsulate many things behind object boundaries, you can’t encapsulate the remote/in-process distinction. An in-process function call is fast and always succeeds […] Remote calls, however, are orders of magnitude slower, and there’s always a chance that the call will fail due to a failure in the remote process or the connection.
The problem with the distributed objects craze of the 90s was its promise that fine-grained operations—like iterating through a list of user objects and setting is_enabled to false—could work transparently across processes or servers. Microservices and agents avoid this trap by exposing coarse-grained APIs specifically designed for remote calls and error scenarios.
We kept modeling our agents as objects even as we distributed them, just using Data Transfer Objects for their APIs instead of domain model objects. This worked well since not everything needs to be an object. Inference pipelines, for instance, are a poor candidate for object orientation and benefit from different abstractions.
At this stage, our system consisted of multiple instances of a few docker images on ECS. Each container exposed FastAPI HTTP endpoints, with some continuously polling our event bus.
This model broke down when we added backpressure and resilience patterns to our agents. We faced new challenges: what happens when the third of five LLM calls fails during an agent’s decision process? Should we retry everything? Save partial results and retry just the failed call? When do we give up and error out?”
Rather than build a custom orchestrator from scratch, we started exploring existing solutions to this problem.
We first looked at ETL tools like Apache Airflow. While great for data engineering, Airflow’s focus on stateless, scheduled tasks wasn’t a good fit for our agents’ stateful, event-driven operations.
Being in the AWS ecosystem, we looked at Lambda and other serverless options. But while serverless has evolved significantly, it’s still optimized for stateless, short-lived tasks—the opposite of what our agents need.
I’d heard great things about Temporal from my previous teams at DigitalOcean. It’s built for long-running, stateful workflows, offering the durability and resilience we needed out of the box. The multi-language support was a bonus, as we didn’t want to be locked into Python for every component.
After a quick experiment, we were sold. We migrated our agents to run all their computations through Temporal workflows.
Temporal’s core abstractions mapped perfectly to our object-oriented agents. It splits work between side-effect-free workflows and flexible activities. We implemented our agents’ main logic as Workflows, while tool and API interactions—like AI model calls—became Activities. This structure let Temporal’s runtime handle retries, durability, and scalability automatically.
The framework wasn’t perfect though. Temporal’s Python SDK felt like a second-class citizen—even using standard libraries like Pydantic was a challenge, as the framework favors data classes. We had to build quite a few converters and exception wrappers, but ultimately got everything working smoothly.
Temporal Cloud was so affordable we never considered self-hosting. It just works—no complaints. For local development and builds, we use their Docker image, which is equally reliable. We were so impressed that Temporal became core to both our inference pipelines and Outropy’s evolution into a developer platform!
Stay tuned for a deeper dive into Temporal and inference pipelines in the next installment of this series!