The Sidecar Pattern as Modernization Aid
SeatGeek had the most heterogeneous technical stack I have seen outside the corporate world.
Historically, they built most of their systems using Python—they even own a popular open-source library I had used wy before even knowing about the company. However, some teams started writing code in Go here and there over the years, plus the eventual Ruby, Java, and Scala used for specific needs.
SeatGeek’s product started as a secondary marketplace for tickets. After years in this niche, the leadership team decided that it was time to expand teh company’s scope and become a primary provider, taking care of everything from seating plans and box office to admission control. The biggest chalenge tto achieve this goal was that SeatGeek is known for being a fast-paced an innovator in the ticketing space but to become a primary ticket provider they had to quickly build hundreds of complicated features and integrations that venues and event producers consider mandatory for any serious player in this space.
In 2017, the company acquired a smaller but much older ticketing company. The intellectual property and software acquired allowed SeatGeek to quickly add these table stakes features to the product and start signing up enterprise clients. The company’s incredible growth has shown this to be a good bet.
The caveat is that these systems added a lot more entropy to our technology portfolio. The systems were built in .Net and running on Windows, something new to the company. They were also built and operated on-premise and had to be replatformed to take advantage of the modern world of cloud computing and scale u to the needs of everything from NFL stadiums with hundreds of thousands of seats to high demand, low inventory Broadway concerts.
SeatGeek is investing heavily in modernizing these systems, with various product and platform engineering teams dedicated to the effort. Still, while folks are heads-down working on the replatforming we still needed to make sure the existing systems are selling tickets and admitting people to their favorite concerts and sporting events. This article is a simplified description of some of the work we have done to accomplish this goal.
The cloud is just other people’s box offices
The first step we took was to was to repatriate and automate the workloads, bringing them to the same cloud where we run the rest of our systems. This was a multi-year effort, documented as a case study by AWS, and it has gone much better than any other lift-and-shift initiative I had been part of. Around Q2 2020 I was very happy to send an email to our data center vendor letting them know that we would not be renewing our contract for the next year, all of our core workloads had been ported to AWS.
As part of the rehosting effort, we built a dedicated infrastructure team focused on building the tools and processes needed to modernize the way these workloads were built, deployed, and operated. We were able to move them to our shared Gitlab and migrate from a deployment process that required people to manually build MSI files and share them via Google Drive to use the same one-click deployment tools we use for the SeatGeek native systems.
But rehosting from on-premise to the cloud doesn’t automatically make the applications cloud-native—or even cloud-tolerant! There are many ways in which an environment such as AWS differs from running bare metal, on-premise servers, and in our case we really felt this pain when it comes to reliability.
These days, we think about reliable systems mostly in terms of crash-only (or at least crash-friendly) software. This term implies that when some partial failure or unexpected condition happens, the system crash safely and recover quickly. This ties in with what the 12 Factor model calls Disposability:
The twelve-factor app’s processes are disposable, meaning they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.
Processes should strive to minimize startup time. Ideally, a process takes a few seconds from the time the launch command is executed until the process is up and ready to receive requests or jobs. Short startup time provides more agility for the release process and scaling up; and it aids robustness, because the process manager can more easily move processes to new physical machines when warranted.
These concepts and principles are table stakes for modern software development. In fact, some infrastructure providers require your systems to follow the 12 Factor model.
The systems we acquired were architected at a different age and for a very different infrastructure. Before the acquisition, they had been deployed either to dedicated physical servers running on small data centers. And sometimes the system was deployed to a small server rack under someone’s desk at a box office!
To reach the desired performance and reliability when running on-premise, the system made a lot of assumptions about hardware, operating system, network topology, and various things that would be considered a big no-no in a cloud computing environment. For example, upon startup, the system would spend a good few minutes building in-memory caches for reference data and in various other optimization tricks. Basically, the systems were as far away from the 12 Factor model as one could get.
Our investiment in automation and tooling had taken us far in our journey, but we would soon learn that it didnt buy us as much time as we thought it would.
The return
As you might imagine, 2020 was a terrible, horrible, no good, very bad year to be in the live events industry. Basically every event was cancelled overnight, which meant a lot of refunding of tickets and dealing with frustrated and confused consumers. Or revenue stalled and we had to reduce the team size. We were able to use the unexpected downturn to accelerate some of our long-term initatives, but it was a confusing and stressful time for everyone.
Thankfully, this didn’t last for the whole year. By the last quarter of 2020, the vaccines were getting closer to being a reality and producers and sports leagues started making public their schedule for the 2021 season, and sell tickets for those events.
I am a big fan of the original philosophy behind the SRE role. Accordingly to classic Google literature, “[SRE] is what happens when you ask a software engineer to design an operations function”. We had invested a lot in the operations side of things, simplifying, automating, and consolidating runtimes, processes and tools. It was time to approach this problem from a software engineer perspective, not just an operator.
That is when I formed a small team composed of Warren Schay and Pedro Reys and gave them the mission to
In general terms, a sidecar is a piece of software that is deployed along another system and augments this system with features it doesn’t support natively. These features can be non-functional, such as providing telemetry or security checks, or more functional, like providing access to a library or component that can’t be imported by the system because it’s written in a different language.
The network is the computer
Most people heard about sidecars in the last five years, but the ideas and usage of this pattern is quite old. In fact, the first design of what eventually became the Internet relied on sidecars by deploying smaller and less expensive computers that provided the network stack to the more expensive computers being connected. From Where Wizards Stay Up Late: The Origins Of The Internet:
An even more difficult problem lay in overcoming the communications barriers between disparate computers. How could anyone program the TX-2, for instance, to talk to the Sigma-7 at UCLA or the computer at SRI? The machines, their operating systems, their programming languages were all different, and heaven only knew what other incongruities divided them. Just before the meeting ended, Wes Clark passed a note up to Roberts. It read, “You’ve got the network inside out.” […] Clark sketched out his idea: Leave the host computers out of it as much as possible and instead insert a small computer between each host computer and the network of transmission lines […]
The way Clark explained it, the solution was obvious: a subnetwork with small, identical nodes, all interconnected. The idea solved several problems. It placed far fewer demands on all the host computers and correspondingly fewer demands on the people in charge of them. The smaller computers composing this inner network would all speak the same language, of course, and they, not the host computers, would be in charge of all the routing. Furthermore, the host computers would have to adjust their language just once—to speak to the subnet. Not only did Clark’s idea make good sense technically, it was an administrative solution as well. ARPA could have the entire network under its direct control and not worry much about the characteristics of each host. Moreover, providing each site with its own identical computer would lend uniformity to the experiment.
The proxies were called Interface Message Processor (IMPs). Eventually the network stack was absorbed by the connected computer, and IMPs became what we now call network routers.

Interestingly, this early use of sidecars accomplishes goals similar to today’s Service Mesh systems. A modern Service Mesh deploys the network proxies that implement its data plane as sidecars, as this diagram from my article on the Service Mesh pattern illustrates:
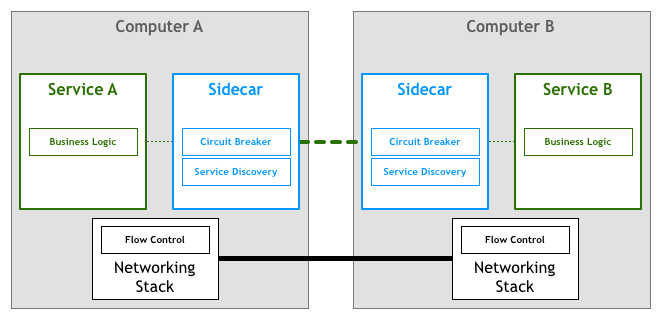
Networking complications have been a driver for sidecars since its inception, but there are many other situations in which this pattern offers an invaluable tool when architecting distributed or monolithic systems. Let’s discuss a real-world example that shows how sidecars can be used to build and manage platform and product software.
Sidecars as init
Sidecars as an outpost
3 months, two weeks, hours to deploy
Sidecars as a a bridge
Prometheus stats mothership
Sidecar Process vs. Sidecar Containers
sroctl feature flags sidecar Sidecars as Outposts Sidecars as initd Sidecars as proxies