Pattern: Public vs. Published APIs
One of the first wtf moments most people have when learning about encapsulation and Object-Orientation is when they realize that keywords such as private or protected don’t really prevent people from calling those methods or attributes. From Java’s basic but practical Reflection framework to Ruby’s powerful metaprogramming features, you can always find a way to access or invoke something that you were not supposed to. “We do all this extra stuff making things private and someone can bypass it all with a few lines of code!?”, asks the confused student.
I wish I could write in this following paragraph that eventually the student has some sort of epiphany and unnderstands the reason why hings such as private, public, and protected members exist. Unfortunately, reality is that most of us will just internalize this as some rule that must be followed or someone will yell at you. Not surprisingly, every few years someone will write a popular article, framework, or a whole programming language based on the premise that these constructs are, in fact, useless and must be abandoned.
But the kind of small systems we have been building in the last decade or so make it such that the lack of understanding and consequent misuse of these concepts isn’t that big of a problem in practical situations. Good type systems, test-driven development, and powerful IDEs make it manageable to work with a badly encapsulated piece of software.
As always, the challenge gets more complicated and more interesting when dealing with this issue at the architecture level, especially in the highly distributed applications promoted by architectural styles such as Microservices or Serverless/FaaS. It also becomes more prevalewnt, as any material channge to a software product built this way requires changing the exposed interfaces of a few different distributed modules.
But the first time I had to deal with this issue, I didn’t even know that I had a distributed system in my hands…
Corporate jailbreaking
Fifteen years ago, I was working on real-time billing for mobile networks. The systems and domain were exciting and complex, but as a junior engineer the tasks assigned to me were to port an ancient system built in C system from Tru64 UNIX to HP-UX. In summary, I spent one year writing #IFDEF and other conditional compilation statements.
Luckily, I was the only engineer in our Latin America office that had any interest in working with Java. Everyone else had taken this job explicitly so that they could work in C, C++, Perl, and nothing else. The company had a product that used a super weird and oh-so-nineties protocol called _USSD . You can think of it as _SMS with session state, it allowed users to check their balance over the phone and other features that were super bleeding edge back then.
The system had been built with state-of-the-art technology. Unfortunately, this was 2004, so it meant Enterprise Java Beans 2.1, a technology so complex and innefficient that a billion-dollar industry was created in developing alternatives to it. As nobody else wanted to even look at it, here I was, 22 years old and the sole maintainer of this gigantic system. The product had already been deployed to various large mobile carriers in Latin America and sold to multiple European clients just waiting for some promised new features to deploy it on their mobile networks across Italy and Germany.
EJBs have changed a lot over the years, but back then their job was to make Java objects accessible via a network with several “enterprise” features added. In theory, using them you would get for free stuff like security, transaction control, persistence, autoscaling, etc. In practice, it never worked properly, and it was super complicated to implement (check out this Hello World tutorial).
In this system’s particular case, if we use Domain-Driven Design ’s terms the original author of the system made every Service or Entity class an EJB. Each of these classes made their methods available to be called over the networkusing a protocol that you can think of as a very underdeveloped version of gRPC. This was not the way the technology was meant to be used, but other than the weird EJB fetish, the system was pretty typical for its era.
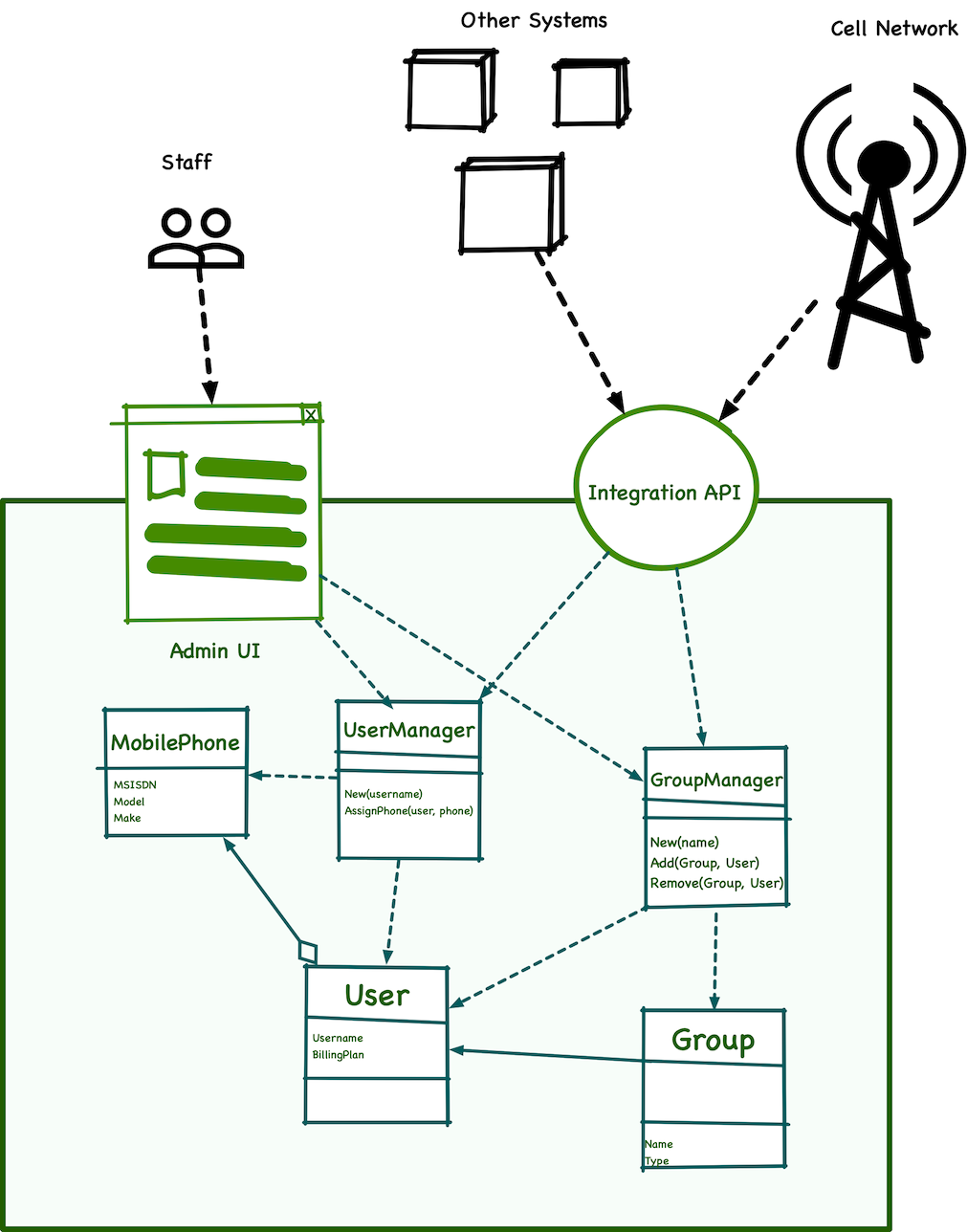
The first thing I did was to get myself a copy of Rod Johnson’s book, the one that eventually became the Spring Framework. Following their advice, I first realized that so many of the EJBs I had didn’t have to be these heavyweight components. The system ran on a single node, there was no remote calls between objects aside from a SOAP API exposed for integrators. I then mapped out the relationships between the objects and started converting as much as possible to simple Java objects (POJOs). Removing the framework-y code allowed me to start writing unit tests and validate my understanding of the code I was reading—a fantastic way to perform code archeology.
After a few months, I made the changes those new clients had asked for and fixed a boatload of known and unknown bugs. I was thrilled with the results, we deployed the changes to our existing Latin American clients and started the plans to onboard the new European ones that had been waiting.
Everything went well. Clients were happy, my boss was super happy. And then the phone rings, with someone yelling at me in Spanish. As a Portuguese speaker, I can understand just enough Spanish to know that he wasn’t happy and that he had a few words to say about my mother.
What nobody in my company knew was that the clients’ IT folks had been tapping into those EJBs to build their own tooling and fill in gaps in our product. They did not have access to the code, but they saw the EJB interfaces that our system exposed and called them from their own systems.
In practice, that green box surrounding my objects didn’t really exist at all:!
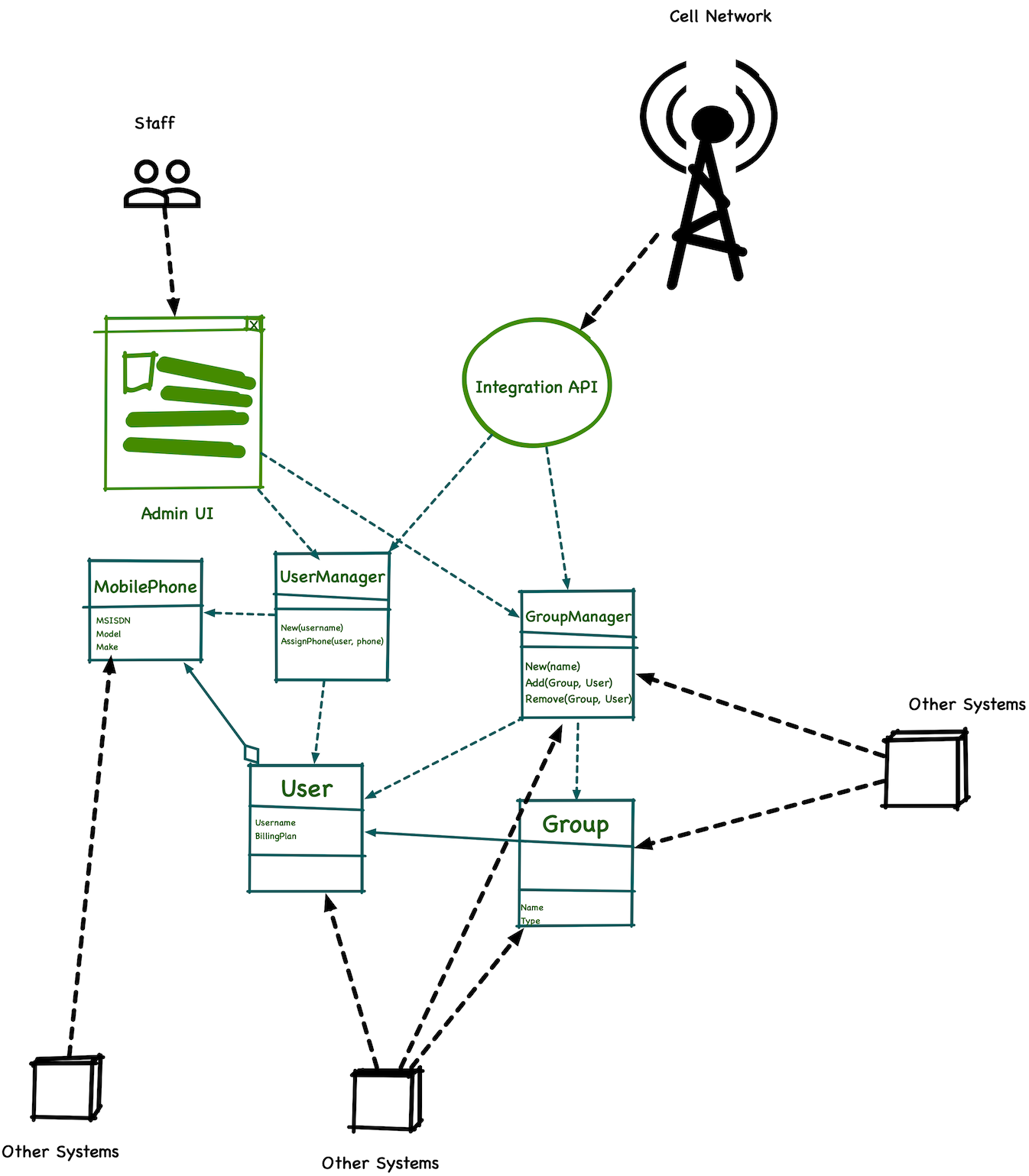
As good UNIX hackers, they exploited the system architecture to better fulfill their needs—pretty impressive, but also super problematic.
The first consequence of this discovery was that I immediately understood how those “internal inconsistency” bugs we had in production and were impossible to replicate happened. The methods that they had been using assumed that any calls were from inside the system, so there was no effort in validating parameters or business rules.
The second takeaway was really scary: given that our clients had built so much around these EJBs, we now had no option but to keep them. All my effort in simplifying the system was fruitless. These EJBs were now our de-facto API, and any change would have to make sure that it didn’t break the various accidental client applications they had built.
Good artists steal?
Taking a more abstract look at the situation described above, I believe that it is yet another side effect of the age-old issue of coupling. Since the 1960s, the industry uses this term to reason about the degree of interdependence between two pieces of software. Over the decades, the focus has changed from lines of code back in the days of unstructured programming to procedures, modules, objects, components, and nowadays services. I tend to use a somewhat modern definition from Scott Bain’s 2006 book Emergent Design:
Coupling is a general term that describes the situation where one part of a system affects another part of the system in some way. Often, in object orientation, we are talking about two classes—one class is coupled to the other, if a change in the second class will cause a change (or a need for a change) in the first. Coupling is usually spoken of in terms of it being a problem, but in fact coupling is not bad in all cases.
From the very beginning, it was generally accepted that lower coupling is the goal, as it allows for two pieces to work and evolve independently of each other. Coupling increases in different ways, some more manageable than others. Here is how Bain talks about these different types of coupling in his book:
Intentional Coupling Versus Accidental Coupling
Bad coupling is usually termed tight coupling. Logical, necessary, helpful coupling is called loose coupling. Loose coupling is ideal; tight coupling is to be avoided.
I am not wild about these terms, frankly. For one thing, they do not stick in my mind, and I always forget whether loose or tight is the bad one. They both sound bad, in a way—loose things fall apart and tight things are hard to take apart and change.
My point is that part of what we are doing in promoting software development as a profession is getting terms like this more clearly defined, and to make sure they inform what we do.
To me, good coupling is coupling I (or you) put into the system on pur- pose, to achieve an end or solve a problem. The coupling that seems to “get me” is the coupling that I did not realize I had because it crept into the sys- tem without any intent on my part.
So, I use the terms intentional for good coupling and accidental for bad. It is not difficult to remember that accidental is bad—just think of a car wreck.
The example we discussed in the previous section, when two systems are coupled in a way that wasn’t planned by the authors, falls within what is called Accidental Coupling.
The industry has found many interesting ways to manage and reduce coupling. Most of these apply the concept of “Information Hiding”, which was first described by David Parnas in his classic 1971 paper “Information distribution aspects of design methodology”.
Oversimplifying the text, Parnas argues that “a good programmer makes use of usable information given [to them]”, and boldly states that those who do not make use of all information available are “usually poor programmers.” If you have been exposed to these concepts before, this might sound very counter-intuitive. Parnas, a demigod of software engineering, doesn’t demonize exploiting implementation details in your favor—in fact, he explicitly says that if you don’t do that you are not a good programmer! But he quickly acknowledges that “a programmer can disastrously increase the coupling by using information [they posses] about other modules.”
This sounds incredibly similar to what happen to me in the scenario we discussed. The mobile carrier programmers were smart and did not want to rely on a vendor—especially one that only release their software yearly and charged them for upgrades—to deal with the practical challenges of their business. Instead, they poked around our system to find out if there was any interfaces they could exploit to get their jobs done. They found out about our needlessly exposed EJBs and made use of this information. They were good programmers that unfortunately had disastrously increased coupling by accident.
Accident Management Process
So what does Parnas recommend to manage the flow of information? Further down on that same text, he makes the point that made this paper and aspect one of the most influential papers in software engineering:
If we want the structure to be determined by the designers, they must be able to control it by controlling the distribution of the information. We should not expect a programmer to decide not to use a piece of information, rather [they] should not posses information that [they] should not use.
This is generally called Information Hiding, and became a basic premise for programming languages, paradigms, design patterns, and the zeigeist of what is considered good software design. Still, there are different interpretations of the idea. Parnas’ own take is pretty literal, as he clarified when responding to a question posed by Adrian Colyer’s 2016 review of the text:
You wrote, “I wonder if in 2016 he would make the claim “making the source code for a microservice available outside of the team working on it is harmful” ??? That would certainly be a statement likely to cause robust debate!” The answer is YES. Papers that I wrote subsequently talk about the need to design and then document interfaces and then give other developers the interface documentation instead of the code. In fact, you can find that in the 1973 papers. The difference is that I have much better techniques for documentation today than I did forty years ago.
— David Lorge Parnas
My experience in this quasi-_security by obscurity_ approach was never very good. v2 endpoints
Instead, I prefer an approach that isn’t focusing on hiding the impolementation details, but rather make it such that people don;t need to know anything about those to use my APis. I tend to call this the “View Source” approach, as https://philcalcado.com/2019/07/30/developer_tools_principles.html .
This is something the unfortunately paywalled Secret History of Hinformation Hiding:
After some reflection I realised that I had found the answer to the question I had been asked by my manager at Philips. The difference be- tween the designs that I found “beautiful” and those that I found ugly was that the beautiful designs encapsulated changeable or arbitrary informa- tion . Because the Interfaces contained only “solid” or lasting information, they appeared simple and could be called beautiful. To keep the interfaces “beautiful”, one needs to structure the system so that all arbitrary or changeable or very detailed information is hidden. … Interfaces are a set of assumptions that a user may make about the module. The less likely these assumptIOns are to change (I e. the more arbitrary the assumptions are), the more “beautiful” they appea r. Thus, Interfaces that contain less infor- mation In Shannon’ssense are more “beautiful” Unfortunately, this formali· sation IS not very useful. ApplICations of Shannon’s theOries require us to estimate the probability of the “signals” and we never have such data
but this still doesnt solve the problem of people using interfaces they shouldnt
support levels, published puckib
It is not clear to me how this would be feasible in a world where less strict Code Ownership models are the norm. In most organizations, people can read and send contributions to any systems develop by their organization, and we use a lot of open source software.
But even in situations when it was easy or desirable to enforce more strict access to , this seems like a different version of security by obscurity. The good programmers would find a way to reverse engineer what they need in no time, just like our clients did in my example.
My experience with this approach isn’t great. In one of the many occasions in which it has backfired, many v1/v2 e1/e2 endpoints documentação melhor no stackoverflow— acho que já falei disso no blog?
Another contemporary way to use novel networking concepts such as a Service Mesh to coordinate which services can talk to which others using mTLS. I have applied a similar strategy with just plain firewalls, but a good Service Mesh such as Linkerd will make this much easier to manage.
Keep what have on parnas, add synopsis for martin, say that it was built for refactoring and I have used it well in this scenario but for distributed apis there’s something missing and it’s hard to teach, break down the dichotomy acc/intention and further into types. Give examples of types (API,seatgeek com, ejb, blabla)
I like the names because they aren’t overloaded too much and accidental.makes me think of fred brooks and most this shit happens because of non fundamental issues
And intentional makes me think of simonyi whom I have learned to respect having spent so many years researching dls
Create a map with all types of API, color code the different types
Find a way to link to bff and maybe purl
Descreve pernas e fowler as Paes road, define public published private internal, cria uma matrix com estratégias para cada estilo em cada api
| Type/Strategy | Parnas | Fowler |
|---|---|---|
| Public | * Security by Obscurity | |
| Private | mTLS | |
| Internal | mTLS/VPC | |
| Published | N/A | N/A |
Send the client log the client t
Flip this part completely. Talk about how parkas said good programmers are basically hackers and then how he says that information hiding is the only way forward. Stress thÏFat info hiding to him literally means hiding (maybe acolyer source code comment). Then talk about how it isn’t about hiding (everything can be hacked, maybe move that reflection stuff here, collective code ownership) and how it is better to create a paved road by making the easy stuff easy. Jump to fowler and justify the use of the word published there as an optimistic way. suggest affordance would be better as just like objects you can use them in many ways but it is the role of the designer to guide you certain way,. Maybe cue to Bloch’s api talk
How that evolved to apis https://www.infoq.com/presentations/history-api/
Devx as a thing.affordabnce?
revisited a lot of the literature on encapsulation and modularization. The most pragmatic reading I found around this theme was Martin Fowler’s IEEE article in which he creates a dichotomy between Public and Published interfaces.
To understand the need for this dichotomy, we need to acknowledge that every system
The article explores how hard is refactoring when methods exposed by objects are used by third parties. interfaces exposed by objects.
The article focuses on refactoring libraries (it calls them components), but the scenario is basically the same as mine:
If I now delete the parameter, everybody else’s code will break when I upgrade. Now I must do something a little more elaborate. I can produce the new method with one less parameter but keep the old method—probably recoding the old method to call the new one. I mark the old method as deprecated, assuming people will move the code over and that I can change it in the next release or two.
Martin
I believe the article distills the issue here to its core in how the author describes the main difference between Published and Public as:
The key difference is being able to find and change the code that uses an interface. For a published interface, this isn’t possible, so you need a more elaborate interface update process. Interface users are either callers or are classes that subclass or implement an interface.
To me, what makes this sentence particularly interesting is that it implicitly acknowledges that this is not a tooling problem, but an organizational one.