Some thoughts on GraphQL vs. BFF
The Back-end for Front-end (BFF) Pattern was originated at SoundCloud. It takes its name from the internal framework we built to make application-specific APIs easier to write and maintain. Since then, it has taken a life of its own, with various articles, books, and open source software that teach, discuss, or implement it.
More recently, another approach to API architecture and design comes in the form of GraphQL. Facebook first developed the technology, and it has quickly become so popular that many startups were created exclusively to build frameworks and tooling around it.
Over the past year or so, I have been asked many times about the relationship between these two. This article is a write-up of my thoughts on the matter.
What is a BFF, even?
I believe that a lot of the questions people have around this topic originate from some misunderstanding of what is the actual goal of the BFF pattern. There is a lot of detail on the background and specifics of the BFF pattern on the original article describing it, but let me try to summarize what I mean by this term.
Let’s take a look at the diagram below:
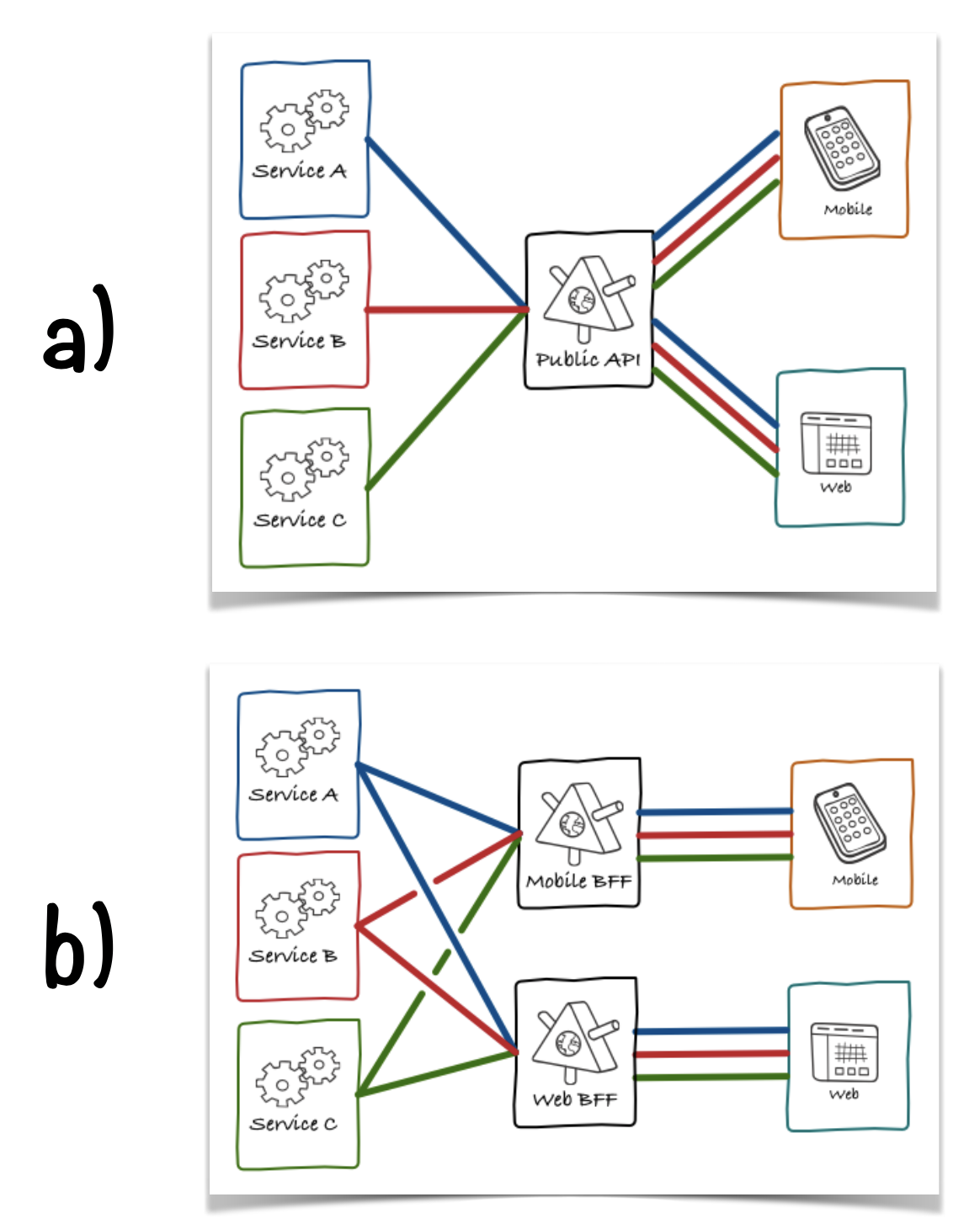
Option (a) is sometimes called a One-Size-Fits-All (OSFA) API, where we have one (or a few) APIs that serve many applications and use cases. Option (b) is generally called BFF, where each application or sometimes use-case has its own API.
In the OSFA model, we usually have many different applications (sometimes built by third-party developers and business partners) share the same endpoints. Every time that one of such endpoints need to be changed, the engineers from the API Team need to make sure that they won’t break any important use cases, integrations, etc. Sometimes people try to go around this challenge by strictly versioning the APIs, but this not only imposes overhead in terms of governance but also won’t prevent you from running multiple versions of the API at the same time, until every client application is able to update their usage.
Instead of trying to apply some strict and more formal governance process to deal with these challenges, with the BFF approach we try to eliminate the problem altogether by giving the team that owns the client applications full control over the API they use.
Putting it in terms from a dichotomy proposed by Martin Fowler, using a BFF means that even if your API might be a Public interface, it isn’t Published. Even if other applications can reach the API—because it is available on the Internet—they are not supposed to do so and this usage isn’t supported by the API owner. Each application then is free to build and evolve their API as it better suits them, with no need to worry about how this would impact other client applications as there will be none.
Something often overlooked when people talk about BFFs is that this new ownership model fundamentally changes the boundaries around your subsystems. In the OSFA approach, the API is a discrete subsystem meant to be used by multiple applications. In contrast, when you have an architecture based on BFFs, the API becomes part of the client application.
The defining characteristic of a BFF is that the API used by a client application is part of said application, owned by the same team that owns it, and it is not meant to be used by any other applications or clients.
Here is an illustration from the original article:
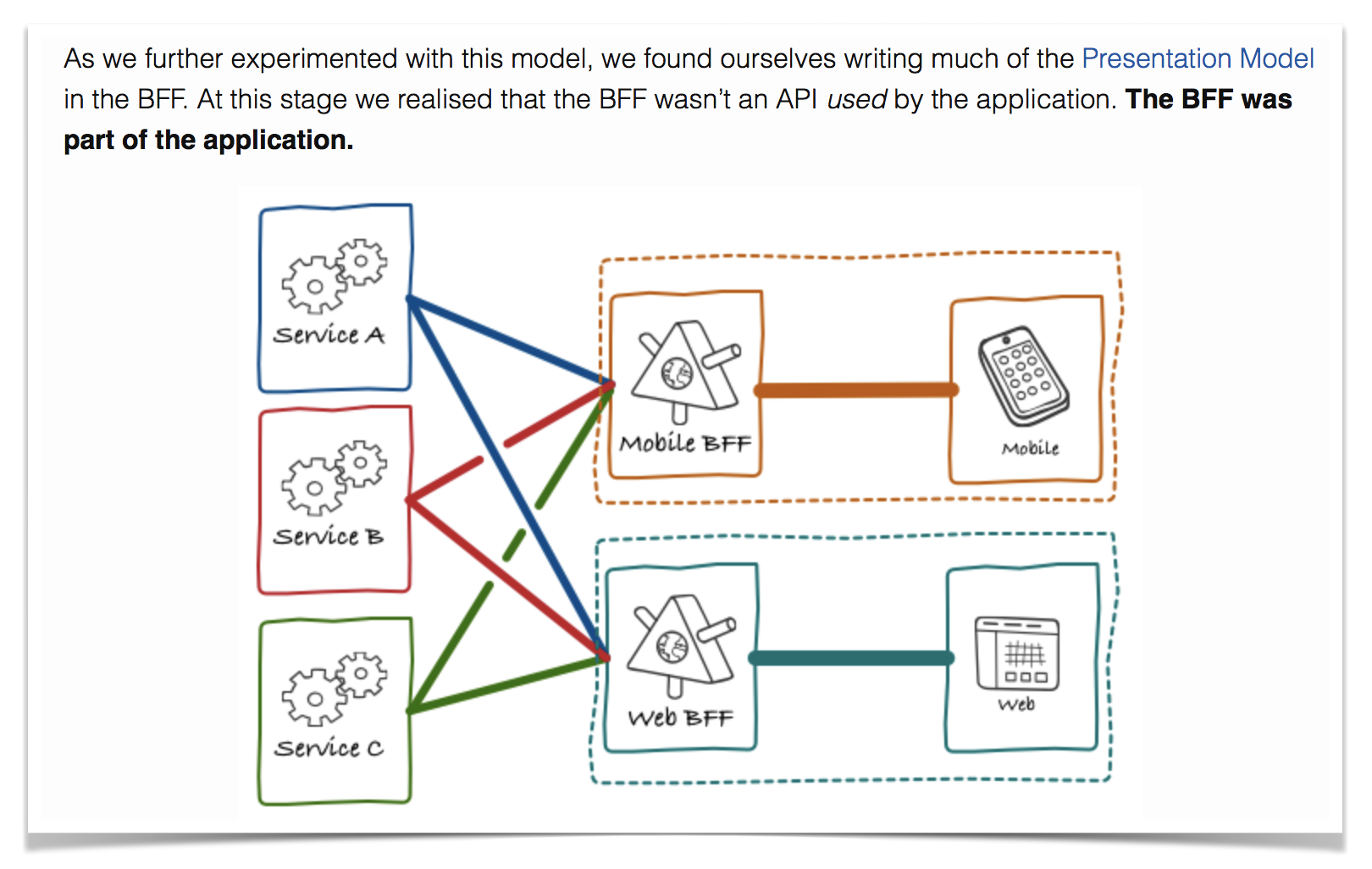
Where does GraphQL fit in all this?
Notice that there isn’t anything in the description above that says that the endpoints provided by a BFF must be optimized for the client application they now belong to. There is no fundamental reason for the API exposed by one BFF to look any different from your typical OSFA API. Nevertheless, when you make the API part of the application, some coupling with the client is not only expected but desired, as teams use the autonomy as leverage.
At SoundCloud, we saw teams using their newfound control over APIs to perform optimizations that made sense for their specific use cases. For example, the Android team experimented with ProtocolBuffers instead of JSON for their APIs payload, the partnerships team was able to allow for much more generous rate limiting settings for our the API used by the likes of Sonos and Apple, and various teams fine-tuned their caching and CDN usage to serve the particular needs better.
So far, nothing discussed here prevents you from using any flavor of RPC you might prefer. You can follow the recipe above for REST, gRPC, GraphQL, SOAP, or any other combination of wire protocol and architectural style you might favor. Better yet, you can have each application using whatever technology suits them better.
It follows then that it does not make much sense to compare BFFs and GraphQL. You can build your GraphQL APIs as many BFFs or as an OSFA API.
I believe that the reason why people struggle with the relationship between these two related but not mutually exclusive concepts is due to one of the most interesting possibilities that BFFs give to client teams: how to optimize their endpoints and payloads.
To recap, here is how the original article on BFFs explains the challenges teams faced with the OSFA approach we had at SoundCloud:
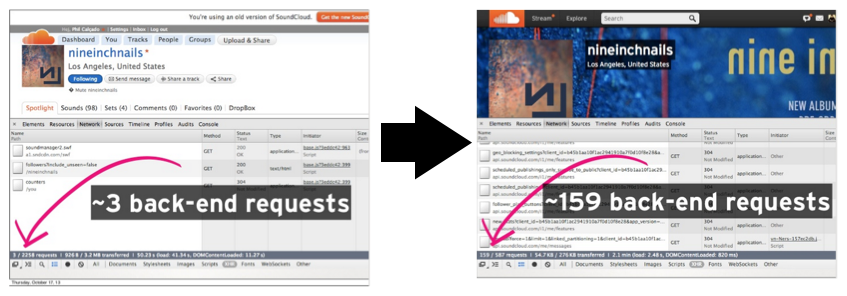
Below you can see how many requests we used to make in the monolithic days versus the number of those we make for the new web application:
To generate that single profile page, we would have to make many calls to different API endpoints, e.g.:
GET /tracks/1234.json(the author of the track)GET /tracks/1234/related.json(the tracks to recommend as related)GET /users/86762.json(information about the track’s author)GET /users/me.json(information about the current user)- …
…which the web application would then merge to create the user profile page. While this problem exists on all platforms, it was even worse for our growing mobile user base that often used unreliable and slow wireless networks.
As we moved to BFFs and let client teams own their own APIs, they started working on ways to minimize the number of calls needed to do things like render the user profile page mentioned above. Our architecture was heavily RESTful, and GraphQL wasn’t even available yet, so the way we dealt with the issue was to model the endpoints in our API following a Design Pattern called Presentation Model.
When using this pattern, instead of assembling a page from many fine-grained calls to the API as described above, we would model user experience abstractions as their own REST resources. For example, we would have endpoints like /track/123/player.json that returns all data needed to render any of the multiple versions of our player.
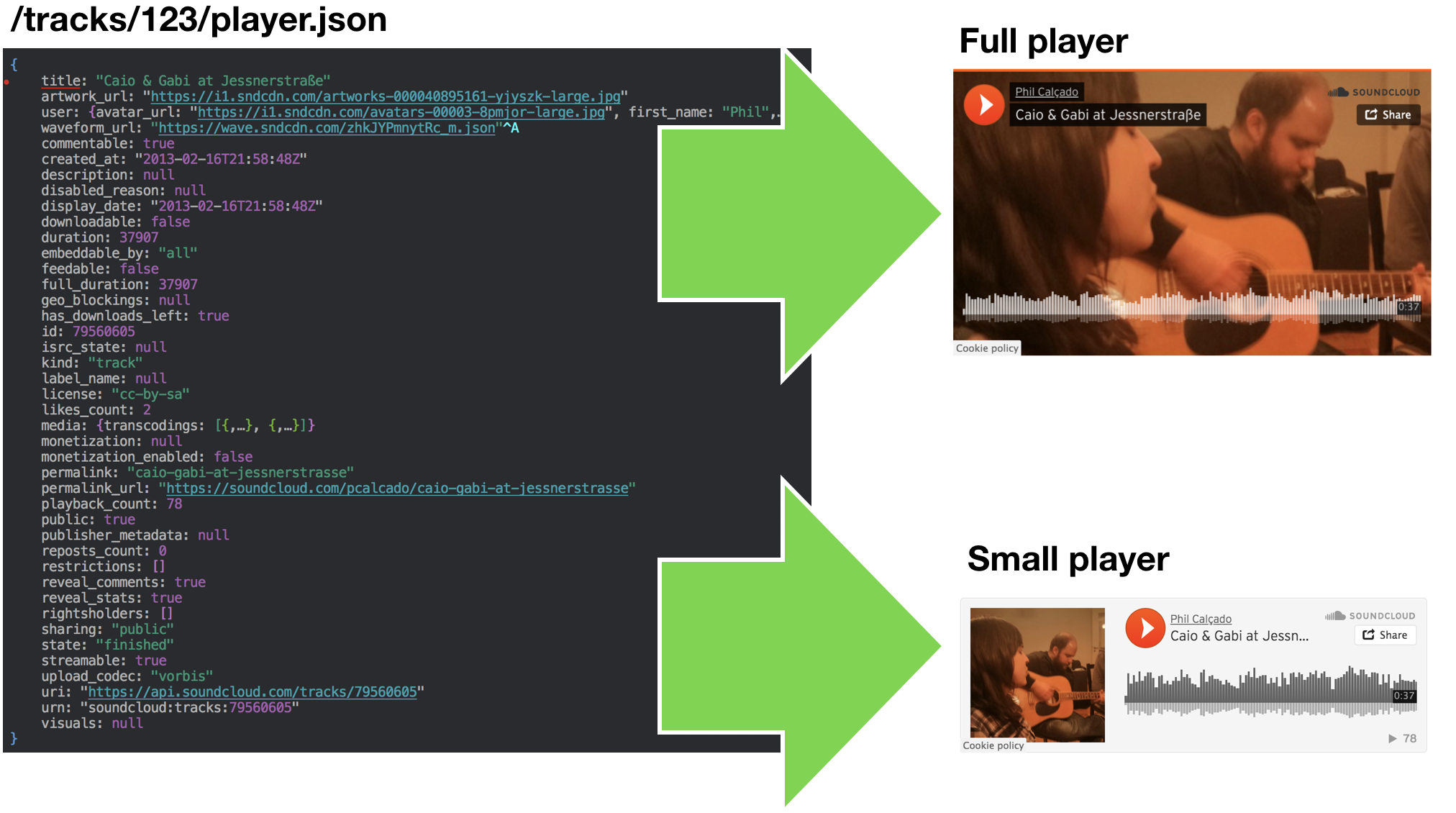
It still requires a page to make more than one call to fetch all data it needed to render the whole screen, but the number of requests needed was drastically reduced, from hundreds to a dozen, and the new endpoints were much easier to manage and reuse.
Were GraphQL available back then and had we decided to use it, things would be quite different. In a RESTful API, the Presentation Model needs to be implemented on the server-side, so that we avoid making all those calls from the example above. When we use GraphQL, we don’t necessarily need a Presentation Model at all, and if we do use one, it can be implemented on the client application, as GraphQL makes it possible to get all data needed in a single request.
One challenge in moving this responsibility back to the client is that it increases the amount of logic that you perform at this layer. It is notoriously hard to make sure that several feature teams are well-staffed when it comes to needs such as mobile development. This leads some organizations to prefer a strategy where they perform as much work server-side as possible, keeping the mobile clients simple and mostly dedicated to display logic. You might also find it difficult to push an urgent change when the deployment process for your app requires going through some kind of approval by an app store.
Do we even need BFFs with GraphQL?
But one more fundamental question that pops up when considering using GraphQL in BFFs is: do we need BFFs at all? As discussed, BFFs are not about the shape of your endpoints, but about giving your client applications autonomy. Still, some GraphQL literature insists that this new technology gives so much freedom to the client by allowing them to perform ad-hoc queries that you can safely have a single OSFA API without the drawbacks from REST-based approaches.
I don’t have enough first-hand experience with GraphQL at scale to have a strong opinion here, but two things about this worry me.
The first friction point is that it is hard for me to believe that you can combine the needs of many different applications, owned by different teams, with different users and use cases, in a single schema. Marc-André Giroux, from Github, has a great article discussing the practical challenges of composing (“stitching”) together schemas coming from different domains. Apollo has published some advanced tooling that aims at easing some of these challenges, but just by looking at this slide from James Baxley’s excellent talk at GraphQL Conf 2019 you can see that there are some non-trivial concepts that need to be applied:

Even if someone comes with a simple technical solution for how to compose schemas, I am not sure that having a single schema is a good idea to begin with. Trying to derive a single schema that holds a complete-ish model of your data and can be queried by wildly different applications reminds me too much of an Enterprise Data Model, which enterprise software development was very fond of just a few decades ago.
In this world, organizations would try to come up with one single database schema, often federated across many instances of Oracle and IBM relational databases, that would be the one source of truth for the whole company. Applications would be built around this enterprise schema, and there were documents that acted as data dictionaries, explaining to developers what each field and type meant. Fowler wrote a few paragraphs on why these Integration Databases can be problematic, and I believe these same issues might arise when you have a single GraphQL schema for your API:
An integration database needs a schema that takes all its client applications into account. The resulting schema is either more general, more complex or both - because it has to unify what should be separate BoundedContexts. The database usually is controlled by a separate organization to those that develop applications and database changes are more complex because they have to be negotiated between the database group and the various applications.
The benefit of this is that sharing data between applications does not require an extra layer of integration services on the applications. Any changes to data made in a single application are made available to all applications at the time of database commit - thus keeping the applications’ data use better synchronized.
On the whole, integration databases lead to serious problems because the database becomes a point of coupling between the applications that access it. This is usually a deep coupling that significantly increases the risk involved in changing those applications and making it harder to evolve them. As a result most software architects that I respect take the view that integration databases should be avoided.
I am looking forward to reading more experience reports on both BFF and OSFA APIs built using GraphQL. At the moment, based on my own experience and what I see from folks like Marc-André Giroux, I suggest that an organization currently invested in RESTful BFFs keep their separate APIs and migrate them to GraphQL, instead of trying to jump to an OSFA GraphQL API.