Calçado's Microservices Prerequisites
In May 2017, I gave a talk at Craft Conf in Budapest focusing on the economics of Microservices. You can watch the video recording here or read through the slides here. In this talk, I have briefly discussed a set of proposed prerequisites for microservices, which are the things I believe you should have in place before considering a widespread adoption of the architecture style. Since the presentation, the list has been referenced by other works in the distributed systems space, so I want to use this post to expand on these prerequisites.
Why bother?
When you decide to adopt microservices, you are explicitly moving away from having just one or a few moving pieces to a more complex system. In this new world, the many moving parts act in unpredictable ways as teams and services are created, changed, and destroyed continuously. This system’s ability to change and adapt quickly can provide significant benefits for your organisation, but you need to make sure that some guard rails are in place or your delivery can come to a standstill amidst the neverending change.
These guardrails are the prerequisites we discuss here. It is possible to successfully adopt a new technology without some or all of these in place, but their presence is expected to increase the probability of success and reduce the noise and confusion during the migration process.
Admittedly, the list of prerequisites presented here is long and, depending on your organisation’s culture and infrastructure, might require a massive investment. This upfront cost should be expected, though. A microservices architecture isn’t supposed to be any easier than other styles, and you need to make sure that you assess the Return on Investment before making a decision.
This is… a lot
It is, indeed. I could try to put your mind at ease and tell you that these are not required for smaller fleets of services, but unless you have a medium to a large fleet, I don’t think you should have microservices. You should start your architecture with the simplest thing that could possibly work.
You don’t need to have sophisticated or even mature answers to the prerequisites stated here. Even at mature companies like DigitalOcean and SoundCloud, we started with very basic implementation. In the beginning, there was a lot of exploration and a boatload of copy and paste.
You should make sure that you have a working answer to each of those items, but do not obsess over it. The answer you have today does not need to be the long-term solution. You will learn more as you go, and at the same time the technology space is maturing, and some of these things are becoming commodity off-the-shelf.
Another option is to forget about microservices and focus the next iteration of your architecture around more coarse grained services. Having fewer moving parts will definitely reduce the prerequisites substantially, and you can always keep reducing the size and scope of your services as your engineering organisation and platform matures.
The prerequisites
As I have first discussed in an older presentation about our adoption of microservices at SoundCloud, I really appreciate Martin Fowler’s work on microservices prerequisites. The list Martin and his fellow ThoughtWorkers have compiled goes like this:
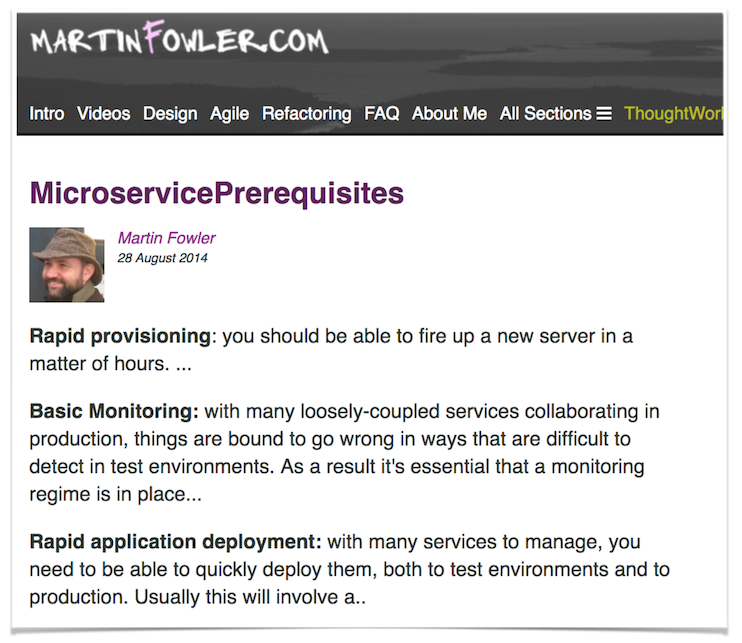
SoundCloud had started our migration towards this architecture before Martin’s work was available, but we pretty much arrived at the same conclusions. As I moved on to my second large-scale microservices implementation, this time at DigitalOcean, we once more confirmed the need for the items above. At the same time, I have identified a few other items missing which have proven themselves crucial for successful microservices adoption:
- Easy provisioning of storage
- Easy access to the edge
- Authentication/Authorisation
- Standardised RPC
So my full list of microservices prerequisites, in priority order, is as follows:
- Rapid provisioning of compute resources
- Basic monitoring
- Rapid deployment
- Easy provisioning of storage
- Easy access to the edge
- Authentication/Authorisation
- Standardised RPC
1. Rapid provisioning of compute resources
Martin says:
You should be able to fire up a new server in a matter of hours. Naturally this fits in with CloudComputing, but it’s also something that can be done without a full cloud service. To be able to do such rapid provisioning, you’ll need a lot of automation - it may not have to be fully automated to start with, but to do serious microservices later it will need to get that way.
He uses the word servers here, but these days you could be using actual servers, virtual machines, containers, functions, or a combination of all these things. That’s why I’ve added “of compute resources” to this item, as it pretty much means anything that will give you some CPU and memory to run your code.
Ten or more years ago, we used to deploy our services and applications on application servers. These were large software layers that multiplexed a single compute unit so that many applications and services could use it at the same time, and this deployment architecture was the norm for many years. Back then, serving a few hundred requests per second was considered Internet-scale and this design allowed for organisations to maximise utilisation of expensive hardware across different services—sometimes even providing multi-tenant services where different companies share an expensive application server.
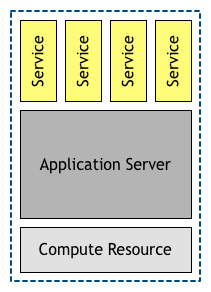
Over time, the cost of compute resources decreased drastically, both on-premise and offered by a cloud. This reduced the need for the application server layer. Even if the application server provided out-of-the-box services to the applications deployed on it (things like automatic security, service discovery, administrative panels, etc.), operating these ever more complicated servers became very expensive. On top of that, as traffic increased we moved from vertical to horizontal scalability, something these products were never good at supporting.
All these forces have led us to the most common deployment architecture used these days, where there is a 1:1 relationship between instances of a service and compute resources.
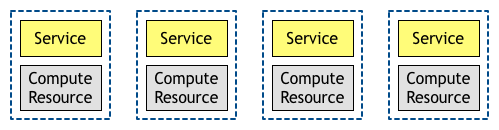
This 1:1 relationship directly impacts microservices architectures. As discussed before, the term microservices isn’t very well-defined but one thing you can be absolutely sure when someone says this word is that they will have lots of small services. Given the deployment architecture described above, this also means that you will have lots of compute units. This creates the need for automatic, fast, and elastic provisioning of compute units to serve the demand of your microservices.
When I first joined DigitalOcean in 2015, I spent a lot of time with my team thinking about our internal systems, the “control plane” of the cloud. Back then it was composed mostly of three different monoliths running on a fixed set of virtual machines defined via Chef databags. It quickly became clear to us that this was a convoluted and error-prone workflow, and it wouldn’t scale. We had to improve our provisioning situation before migrating to microservices.
The team tasked with fixing this problem decided to use containers and Kubernetes as our new compute platform, and we spent the first six months of 2016 both making sure that all new services were deployed on this new system and migrating the legacy monoliths to it. This step enabled us to move ahead with our architecture changes while still working on the many new products we had to release. In fact, our monitoring and alerting offering was the first product developed in the new system and acted as a tracer bullet shaping the backlog and priorities for the platform team.
2. Basic monitoring
Martin says:
With many loosely-coupled services collaborating in production, things are bound to go wrong in ways that are difficult to detect in test environments. As a result it’s essential that a monitoring regime is in place to detect serious problems quickly. The baseline here is detecting technical issues (counting errors, service availability, etc) but it’s also worth monitoring business issues (such as detecting a drop in orders). If a sudden problem appears then you need to ensure you can quickly rollback, hence…
As mentioned above, a microservices architecture is a complex system. There is only so much that you can control and predict. A lot of this chaos is driven by the state of continuous change, as services are deployed and redeployed many times a day.
It turns out that this problem is not exclusive to microservices. In fact, John Allspaw and others have been building a toolbox around these challenges for almost a decade now, while working on monolithic architectures for Flickr and Etsy. In his work, Allspaw has documented something critical when dealing with fast-paced change:
Put another way:
MTTR is more important than MTBF
(for most types of F)
What I’m definitely not saying is that failure should be an acceptable condition. I’m positing that since failure will happen, it’s just as important (or in some cases more important) to spend time and energy on your response to failure than trying to prevent it. I agree with Hammond, when he said:
If you think you can prevent failure, then you aren’t developing your ability to respond.
Mean time between failures (MTBF) is the elapsed time between failures of a system during operation. Mean Time To Repair (MTTR) is the average time required to fix a problem in operation. In simplified terms, MTBF tells you how often failures happen while MTTR tells you how quickly a problem is solved once detected. In a system in constant change, you cannot control MTBF, so it’s better to invest in having a great MTTR.
As you start investing in reducing MTTR, you start realising that way too often that reducing recovery quickly arrives at diminishing returns. Time-to-recovery isn’t the only step in incident management, and sometimes it isn’t what takes the longest chunk of the time spent on it. Over and over again I have seen that the most painful part of incident management is the Mean time to detection (MTTD). This metric reflects the time elapsed between an incident happening and an operator detecting it, which then triggers the recovery process.

This makes you realise that you need to invest in telemetry to quickly detect problems. Although this need exists in any architecture style, microservices do add some different challenges here. In a monolithic architecture, you always know where the problem is: it’s obviously in the monolith! What’s left is to find out in which class or function that problem lives. In this world, sophisticated tools like NewRelic can help you go down to the code level to detect the problem:
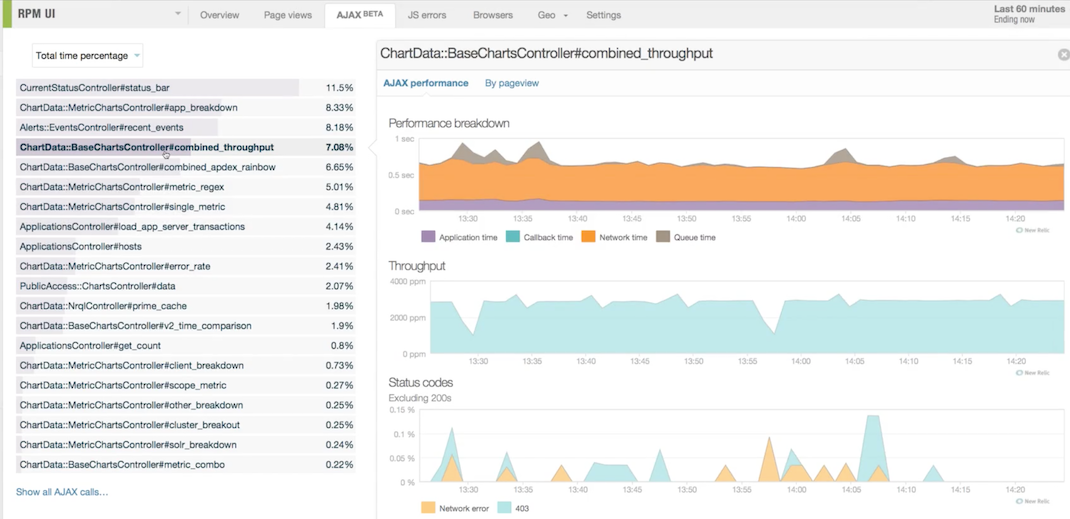
While these tools are also widely used in microservices architectures, they are only helpful after you have detected which service or services are behaving in unexpected ways. Because many services collaborate to fulfil each request, you also need to make sure that you can compare services against each other, which allows for you to pinpoint outliers and not get distracted by environmental issues.
So you should prefer basic telemetry across your whole microservices fleet over a lot of detailed telemetry of a few core services.
At SoundCloud, our experience in monitoring of microservices led us to focus on standardised dashboards and alerts. We made sure that every single service exported a common set of metrics, with the same granularity. We then used these to build dashboards, first on Graphite and eventually on Prometheus, that allowed for us to compare these metrics across different services.
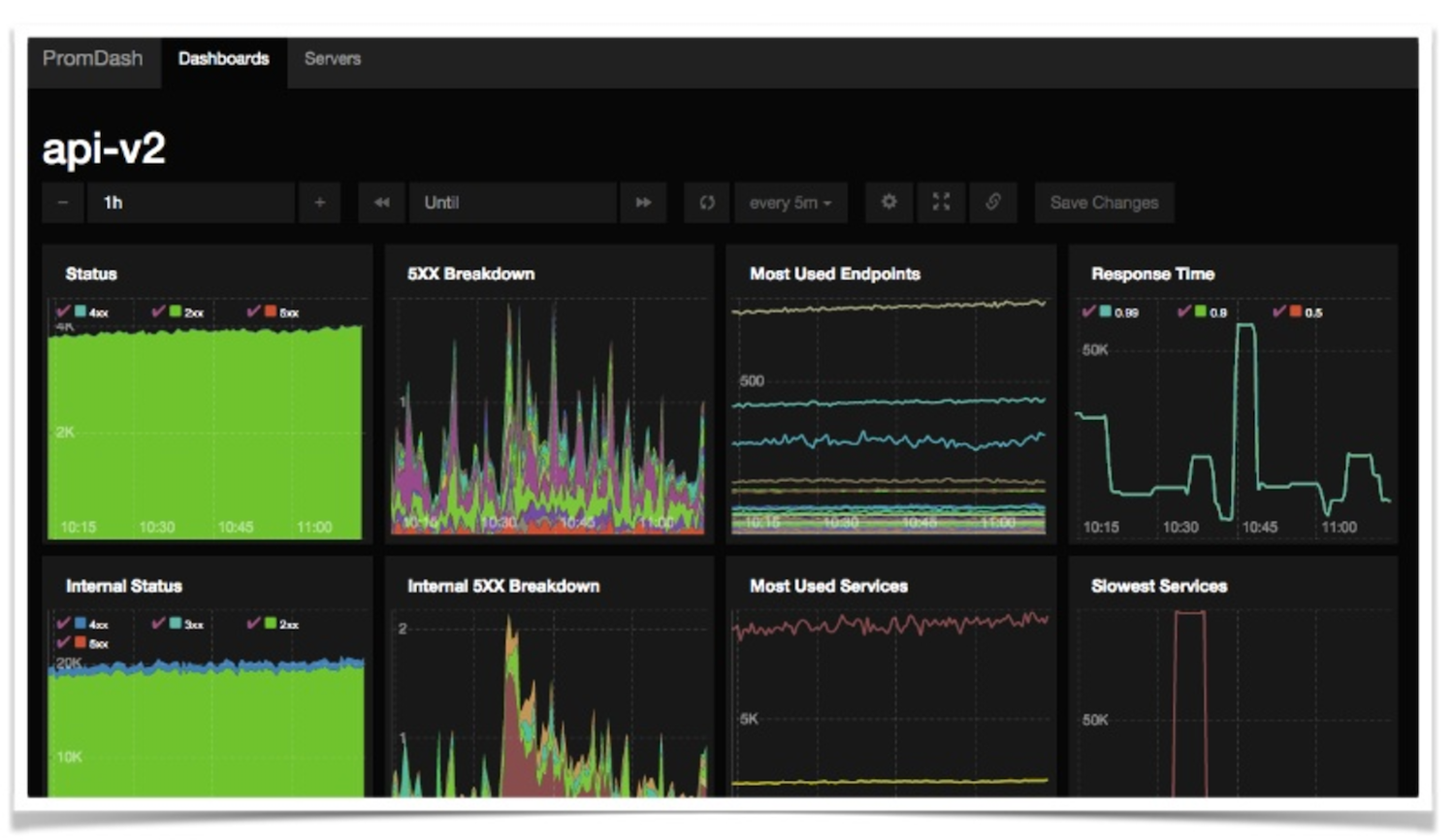
The dashboards provided us with the insight we needed to reduce our MTTD, but we quickly realised that it wasn’t enough. With hundreds of services deployed all the time by dozens of small teams, you need to be able to correlate potential issues with changes, both deploys of new code and changes in infrastructure. In our case, we built a small service that returned a feed of all changes made by engineers and by automated tools. We changed our deployment tooling to make sure that every change, even when you are just scaling up a service by adding one or two more instances, would be reported to this feed.
Checking for any recent changes became the first step in our incident detection workflow.
3. Rapid deployment
Martin says:
with many services to manage, you need to be able to quickly deploy them, both to test environments and to production. Usually this will involve a DeploymentPipeline that can execute in no more than a couple of hours. Some manual intervention is alright in the early stages, but you’ll be looking to fully automate it soon.
Martin proposes this item as a direct follow-up to the previous one. He states that a speedy recovery from an incident is likely to require the deployment of some new code or configuration, and because of that deploys should be as quick and deterministic as possible.
I wholeheartedly agree with that, but to me there is another fundamental driver for this prerequisite that is not directly related to incident response. With a single monolith it is ok to have a cumbersome and very manual deployment process. Even if the cost-per-deploy is high regarding both the steps that the operator needs to take and the risk of a mistake, in the end, it will often pay out as each deployment will usually contain many changes, impacting various features and developed by different people and teams.
With microservices it becomes the other way around: a single change to a single feature might require deploying many services. You will have to perform many deployments of different services, and it is important that each one of these deployments is inexpensive and has very low risk. As Martin mentioned, build pipelines tend to fit the bill perfectly here.
This is the prerequisite we struggled with the most at SoundCloud. Our monolith was deployed using Capistrano and shell scripts, in a long and interactive process. The file containing instructions on how to do deployments was so complicated and had so many corner cases that it was often referred to as tax_code.md.
As I first described in SoundCloud’s engineering blog, in the beginning we had decided that our services could be written in any language and runtime teams felt comfortable with. This strategy had several advantages, but amongst its disadvantages was that we could not make assumptions about how applications were deployed. We had .jar files, Ruby scripts, Go binaries… everything. As the minimum common denominator across all code bases, we standardised that:
- Every service had a Makefile sitting in the root of the service code’s directory. This script had a
buildtarget, even if all it did was to invoke another build system like SBT or Rake. - Once the make command finished, the deployment tooling would create a SquashFS artefact containing everything in that directory, including the code, assets, and generated binaries.
- The code should also include a Heroku-style procfile that described how to run each process. After the SquashFS image is deployed, the operator had to scale up/down versions of processes the same way you’d do it in Heroku.
This process allowed for us to scale to a dozen or so services, but the number of required manual steps was too high, which introduces risk. To make it worse, these lower-level primitives didn’t directly support more interesting deployment techniques, like blue/green deployments, canary servers, and even A/B testing. Because of these issues, most teams ended up building their own glue code on top of the provided tooling. As these scripts were seen as side-projects, their code quality varied drastically. We had a couple of big production incidents caused by some defective scripts.
As we grew from a dozen to close to hundred services, we invested in better tooling for our deployments. The biggest difference was that we moved away from deploying from an engineer’s laptop to build pipelines (we started using Jenkins but eventually moved on to ThoughtWorks’ GoCD). The heavy automation led us to more deterministic and faster builds, which is exactly what one needs when the number of deployments per day goes from one to hundreds.
4. Easy provisioning of storage
Most companies coming from a monolith into Microservices will have a single, large, well-maintained database server. After many years as the single storage for data, this database setup is usually well-tuned, with many replicas, and well-integrated with other systems like your search engine and data analytics tools.
There are many challenges in using this monolithic database, though, and most of them are related to updates to the schema. Changing or removing tables and columns require manually making sure that no code, either via programming or metaprogramming, relies on the old structure. After a few years, every classic database refactorings has been applied to the monolith and in-house tools have been written for the most common ones.
Nevertheless, it is still very common for teams adopting microservices to re-use the shared schema. “Just one extra table/column/view won’t be a big deal”, think the engineers while being slowly murdered by a million paper cuts. On top of the change management overhead described above bringing your velocity down, you are also a JOIN away from data coupling between services that should never know about each other’s internals.
The main reason for this trend in companies migrating to microservices is that the organisations tend to invest a lot in provisioning and deployment but forget to offer a reasonable way to have a storage system teams can rely on. Even if spinning up a MySQL server only takes a few seconds there are many items that one must pay attention to when making these isolated systems anywhere close to production-ready. Replicas, backups, security, tuning, telemetry, and several other aspects matter a lot, and very often your engineers have zero experience in setting up and owning a database system.
If you are working on a cloud-native architecture, one of the many Database-as-a-Service offerings allow for you to outsource these operational tasks to a vendor. At a cloud provider like DigitalOcean, we didn’t have this option—we were the infamous other people who own the computers. We had a medium-term plan to provide quick-and-easy provisioning of MySQL databases for internal use, but the first step to unblock our move to microservices had to be much less ambitious. Instead of building sophisticated tooling from the get-go, we invested time in cleaning up and documenting standardised Chef cookbooks and related scripts that would make it possible for any team to spin-up a production-grade MySQL server without too much hassle.
5. Easy access to the edge
The very first microservice in an organisation is usually written in isolation, by a single person or small team investigating the approach as a solution for some of the challenges they experience. Because the scope of this service is usually very small, it is common for the author to get a working version in their development and test environments in no time. Once it gets closer to making it to production, the engineer faces the question: how do I expose this new thing to my external users, those outside my local network?
Similarly to the challenges around databases, the main issue here is that prior to this moment nobody in the company had to think about this problem. The monolith has been exposed to the users and likely the whole public internet for many years. It has all sort of features that protect your internal VPN from malicious or mistaken users. Rate-limiting, logging, feature-flags, security, telemetry, alerts, request routeing… it’s all there.
For some reason, the most common strategy for this first microservice seems to be exposing it directly to the internet, either under a different hostname or a special path.
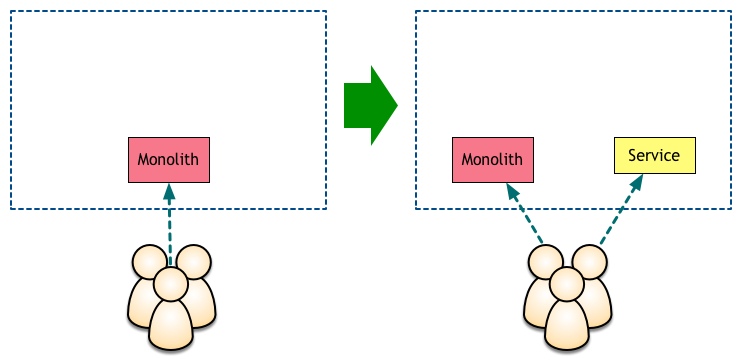
This technique relies on having the client, often a mobile or single-page application, combine the results of requests to multiple endpoints. This can work well enough for one service, but the model tends to break as more services are added.
Not only does the client code become increasingly complicated, but exposing a service on the public internet isn’t a simple task. If you take your customers and users seriously, you need to make sure that internet-facing systems can deal with all sort of incidents, from malicious users to unexpected peak traffic. Having every single service deal with this increases the cost-per-service considerably.
This was the exact scenario for our first few services at SoundCloud. With hundreds of millions of users, it very quickly became clear that we needed to limit which services were exposed to the internet. We thought about building a gateway to bind all services, but with a small engineering team and a lot of product features to deliver we needed an intermediate solution.
In our case, we started using the monolith as our gateway:
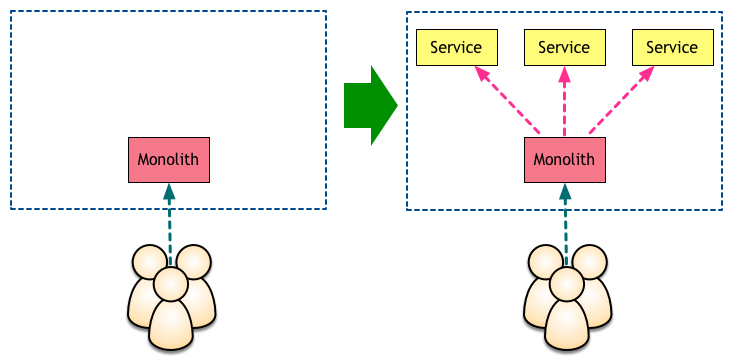
So each request would first hit the monolith, which then would call other services in the background. This strategy worked well for the next few services, but it had several issues. The first problem we detected was that it created some weird coupling between the new services and the monolith, in which changing a service would often require a change in and redeploy of the monolith. On top of that, our monolith was running a very old version of Rails. Without good concurrency we had to rely on serialising requests to all those new services. Our request times were increasing with every new service we added.
Over time we invested in a proper gateway, which was introduced at the same time as we migrated to the BFF Pattern.
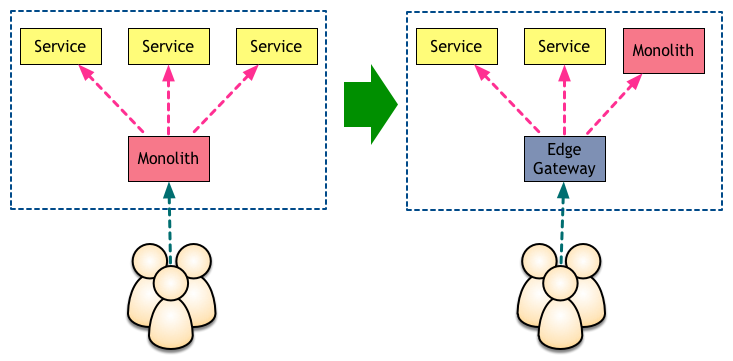
We followed a similar path at DigitalOcean, but because we had three monoliths instead of one we migrated to an edge gateway much earlier.
6. Authentication/Authorisation
Another important component that we usually only think about when the first microservices are getting close to production is how does a microservice know who is making this request and what kind of permissions they have? The naïve approach to this problem is having each microservice require the user identifier as part of all requests made to it and then check this against your user authorisation/authentication system or database.
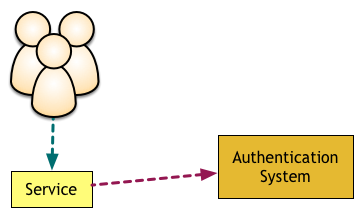
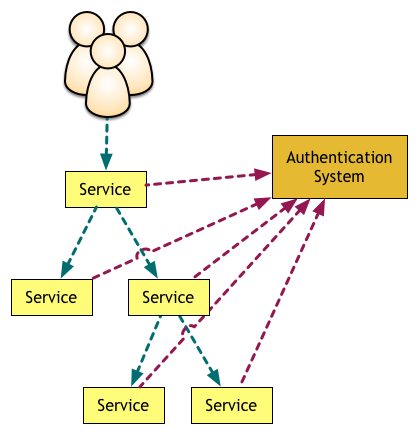
This might be good enough when you have a single service, but the more services you add the more redundant and expensive calls you will be making to the authorisation system:
At SoundCloud, while we were using the monolith as the edge gateway we already had in memory information about who the user was and what they could do. We changed our HTTP client code always to pass on this information as a header in all HTTP requests coming from the monolith to downstream services.
Once we moved to the edge gateway approach, we decided that this component would make one request to the authentication service, and forward not only the user URN but also geolocation information and OAuth scopes available to that request in every call it made to downstream services—in the music industry, what you are allowed to access depends on which country you happen to be in just as much as on who you are.
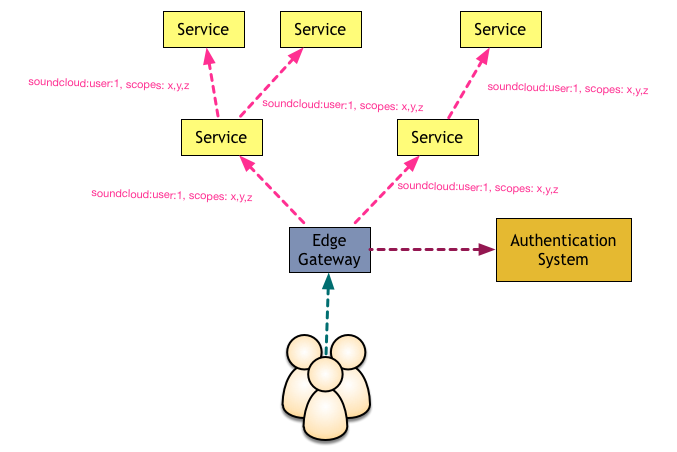
This more sophisticated setup was possible once we migrated most of our internal services to use the our internal SDK for microservices, based on Finagle.
7. Standardised RPC
This last point is less contentious but nevertheless important. You have all these components in your architecture, and they all will collaborate a lot, and in unpredictable ways. You need to make sure that they can talk to each other, which means both being able to understand the way bytes are sent down the wire but also what conventions and standards are in place.
At SoundCloud, the obvious choice for our initial services was HTTP and JSON. Unfortunately, saying “just use HTTP and JSON” doesn’t actually buy you much. These formats won’t tell you how to send authorisation information, how to do pagination, how to do tracing, what architectural style for RPC to use, how to handle failures, etc. We also started suffering performance issues with the heavily textual protocols, and some more data-intensive teams moved on to use Thrift.
For any company moving to heavily distributed architectures today, I would suggest gRPC for all your internal RPC. On top of that, every time you need to serialise a message, say to post it on a bus like Kafka, you should use protocol buffers so that you have the same serialisation protocol across both push and pull use cases.
gRPC and protocol buffers on themselves won’t offer you everything you need. At both SoundCloud and DigitalOcean, I had to staff a team solely focused on building tooling around RPC for microservices, something most companies can’t afford doing. These days we have an interesting solution in the concept of a service mesh, which is “a dedicated infrastructure layer for making service-to-service communication safe, fast, and reliable”. As a longtime Finagle user, my favourite player in this game is linkerd, but there are several options in this space.
Acknowledgements
Andy Palmer, Dave Cameron, Mike Roberts, Daniel Bryant, Rafael Ferreira, Vitor Pellegrino, Andrew Kiellor, Marcos Tapajós, Douglas Campos, and Carlos Villela gave feedback on drafts of this article.