Pattern: Using Pseudo-URIs with Microservices
I’ve spent some time talking about the very basics you need to have in place before thinking about going down a microservices route, but even if you have these in place that doesn’t mean that you aren’t going to find some new surprises. Microservices impose a very distributed architecture, and this requires us to re-visit many concepts that are considered a solved problem in more traditional scenarios.
One of such concepts is how we implement identities for objects. This is usually a no-brainer in more monolithic architectures but it becomes a more interesting challenge as we have more distribution and collaboration between services.
How I understand object identity
Before we discuss how things change in a distributed services scenario, let’s try to build a working definition of object identity.
The first thing to clarify is what mean by the word object in this text. While we are going to use some Object-Oriented literature here, in this text object means a bag of data with cohesive attributes that likely model an abstract concept. If they include behaviour besides the state or if they do message-passing isn’t relevant to this discussion.
In his classic book, Bertrand Meyer describes some challenges in working with the unique identity of an object:
I1. Two objects with different identities might have identical fields
I2.Conversely, the fields of a certain object may change during the execution of a system; but this does not affect the object’s identity
I would like to add a third challenge here. This is something that becomes commonplace when you have code that stores objects in persistent storage, like a database, or has even minimal support to parallelism:
Two distinct object instances, with or without identical fields, might have the same identity and hence represent the same object
Basically, in any modern system you should always assume that there can be more than one instance of the same object in memory at any given time.
Meyer then defines object identity as the property of an object that helps to deal with these challenges:
A property that uniquely identifies an object independently of its current contents (fields)
Something tricky about this idea is that there is no automated way to define meaningful identities. What makes two objects have the same identity or not depend on their business domain and the application logic. In most programming languages, it is up to the programmer to define identity, usually by overriding an equals() method or implementing some protocol or type class that is then used by their code, third-party libraries and the runtime in testing for identities.
Although this represents more work for the programmer, it also allows for a lot of flexibility. Because languages and runtimes make no assumptions about equality, we can implement some sophisticated techniques, such as the Value Object and Entity patterns.
Using simple numeric identifiers
Even if Value Objects are very useful in certain situations, the most important objects in our systems tend to be Entities. This means that the object should be able to change state (e.g. when a user changes their home address or changing marital status) while keeping the same identity (changing addresses or getting married or divorced doesn’t change who the user is).
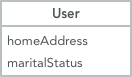
Historically, implementing identity for Entities has been very simple: just use the primary key (or similar unique identifier in whatever persistence technology you use) as the attribute that identifies a unique object, usually called id.
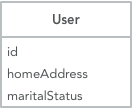
This direct relationship between some database-specific identifier and an object’s identity can lead to several problems. One of these potential issues is how coupled your objects become to the specific database implementation. Another challenge is that might raise some potential security or privacy concerns. But, even with these challenges, this strategy is usually considered good-enough for most cases. In fact, it is the default identity implementation for various popular frameworks and tools.
In a Monolith First approach, this is the most common way to go about object identity. As we move an architecture towards further distribution of components, some new issues arise. Let’s discuss some of the challenges one might find as the number of distributed services and the scale of their usage increases.
Enumerability
The way most databases and frameworks use automatic identifiers is monotonically incrementing an integer, i.e. the sequence goes like 0,1,2,3,4.... While enumerable identifies have many benefits, including providing a cheap way to sort your data by recency, leaking this detail to your clients and users can cause some serious headaches.
Building your identifiers on an enumerable sequence makes it simple to enumerate all of your objects. If you tell me that my comment is available at http://blog/comments/16020 I can write a shell script that tries to download the contents of all URLs from http://blog/comments/1 to http://blog/comments/16020. It also makes it easy to guess how big your dataset is: if I write a new comment on your blog and its ID is 16020, I can be reasonably sure that you don’t have more than 16020 comments across your whole blog.
As mentioned before, making it easy to guess URLs and identifiers may bring some questions about privacy and security, but we can avoid these with proper authentication and authorisation controls. In my experience, the real problem with how easy it is to guess your identifiers has more to do with business reasons. In an industry made mostly of venture capital-backed private companies that use their growth and engagement numbers are currency, allowing for third-parties to guess how many objects you have, how many of those are active, etc. is never great.
Distributed generation
Just like with underlying infrastructure systems, one way to structure microservices is to segment or shard your systems. There are many different ways to split your shards, but one popular strategy is to distribute them globally. Besides the benefits it brings to the storage of large data sets, this also allows for your architecture to make sure that a user or client system is served by a service geographically closer to them, which tends to improve the quality of service. Let me illustrate this with an oversimplified picture:
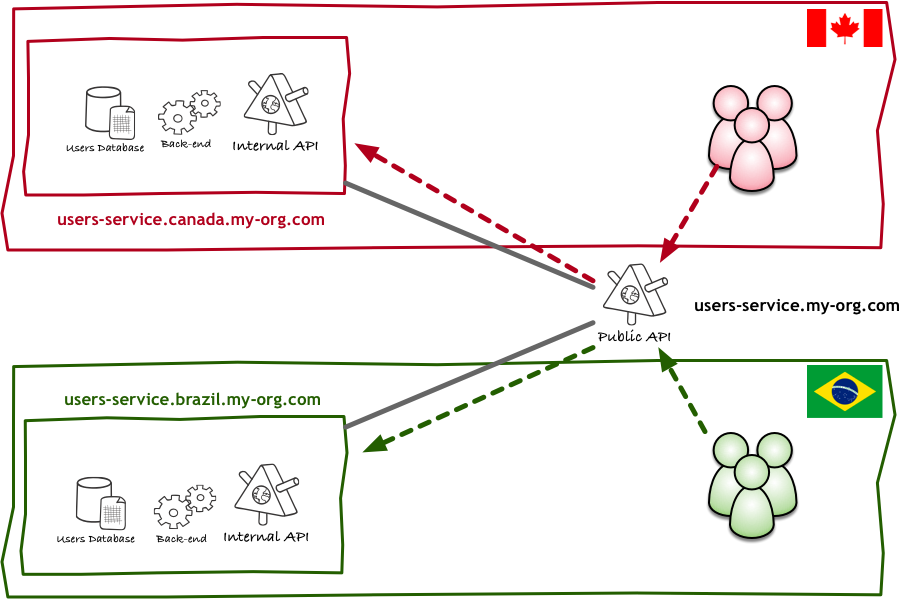
The kind of architecture described above is more common in systems with millions of users and global footprint, and most organisations will never reach a scale to justify it. In any case, privacy regulations, patent law, and various other external factors may require the engineering team to deal with some of these constraints before there is an actual scalability need.
Irrespective of what needs have driven you towards geographic distribution, one characteristic of sharded systems like these is that you will have different instances of a service, with different databases, creating instances of the same object. In the diagram above, both instances of the user service would be creating and deleting users. Still, when you want to perform any operation across all users in the organisation, you will need to create a list that contains users from both shards.
If you are using simple auto-increment strategies to generate your identifier you will likely have to allocate different ranges to each system (e.g. Brazilian users have id between 1 and 1000000, Canadians between 1000001 and 2000000). Managing these ranges can become a nightmare, especially as you add new shards to the system.
Data type coupling
Integers are the most common data type used by databases to implement automatic primary key fields. Databases support many different types of integers, some larger than others. Database experts will often try to make sure we use the smallest type that fits our needs, making it possible for the database engine to be efficient about how it stores and queries data. It is very common for APIs, internal or public, to let client applications know the data type of the identifier, so tht they can make sure their system can also be optimised.
While the advantages of sharing the data type information with clients are clear, leaking this implementation detail can lead to some challenges. It is very common for a successful product to reach a point where the optimal data type chosen at first isn’t enough anymore, you almost literally run out of integers.
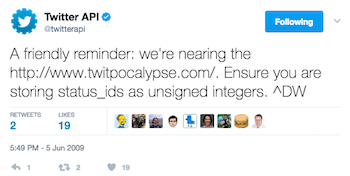
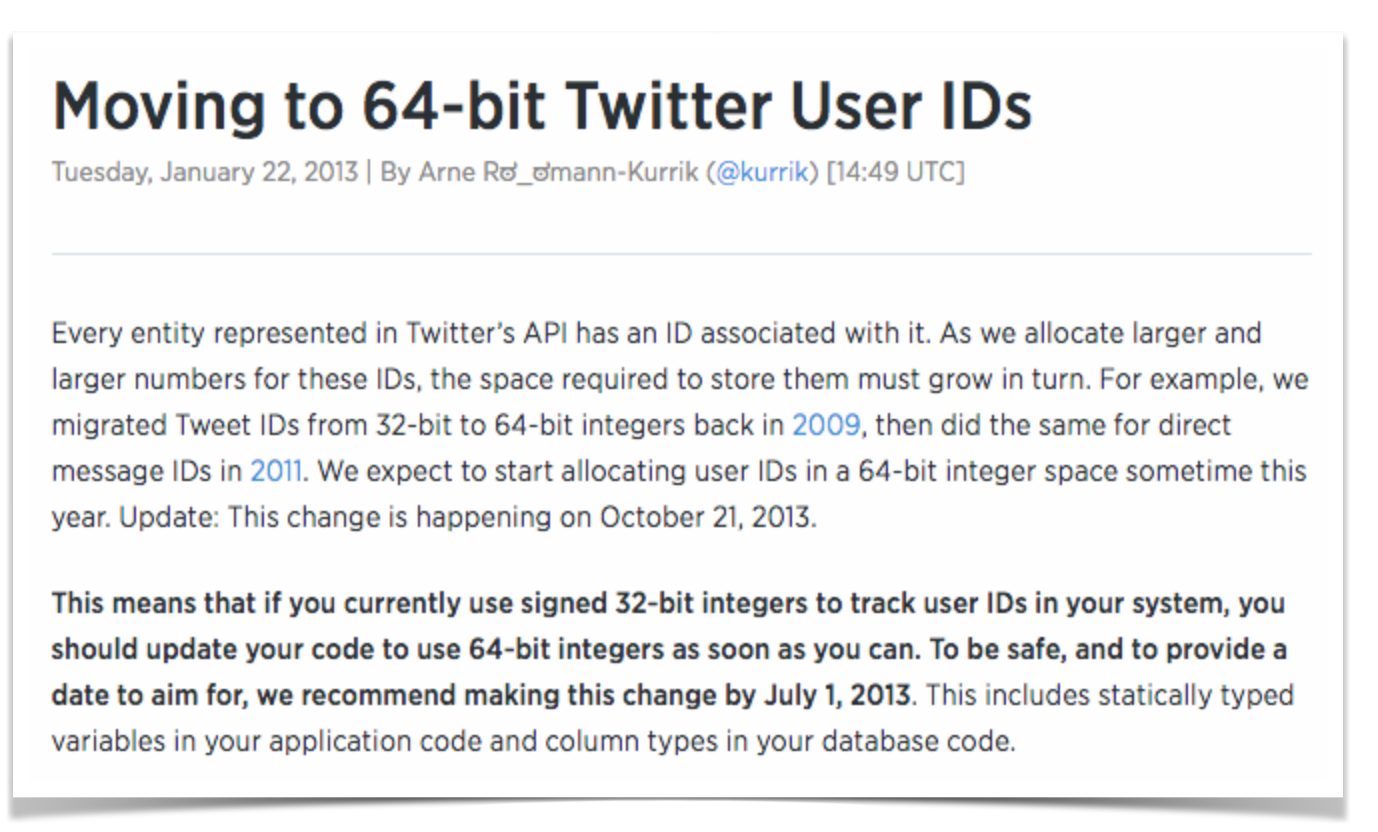
Probably the most well-known occurence of this problem was what Twitter faced around 2009, during what the tech media dubbed The Twitpocalypse:
Twitpocalypse is the name given to a bug that’s about to be exposed. Apparently, it’s similar to the Y2K bug in its nature, and stems from the fact that every tweet sent out has a unique numeric identifier. This identifier is about to hit 2,147,483,647. This number is the signed integer limit and apparently when some third-party Twitter clients start hitting it, the identifiers will start turning negative, and those apps are likely to crash as a result.
Back then Twitter depended a lot on thrid-party clients and tools. They needed to make sure that the changes they had to implement to fix the problems would not break clients. As the end was near, some of the first steps were to ask clients for small changes:
As they changed their internal systems and architectures to cope with this and other scalability issues, Twitter made several other changes to how it generates and stores identifiers. As discussed in a previous section, something they had to do as to move away from sequential identifiers, even if they were able to keep the new identifiers partially sortable. With the changes, Twitter has asked folks to use larger integer types, but they still allowed clients to make assumptions about the identifier being an integer:

Over the next few years, they converted most of their identifiers to the new numeric formats. Even four years after the first incident, every time they’d execute a change like this, they had to make sure that their clients were ready for it:
But even if clients would adapt to the changed implementation details, eventually the larger size of integers caused some interesting problems. Like when one tries to use JavaScript to parse identifiers:

Third-party developers are always harder to steer and collaborate with than internal clients working for the same organisation. Nevertheless, my experience in larger scale microservices architectures is that the more implementation details you leak, the more your service’s clients will depend on it. Big refactorings, even of your own services, can be really hard to orchestrate and execute.
Mixed collections
The last issue I want to explore with simpler identifiers doesn’t have to do with databases or integers, but how implementing object identity in distributed systems is often is more complicated than we intuitively think about it.
Back in early 2011, I was interviewing at SoundCloud. When talking to the CTO, he had to cut short our Skype session because, for the fourth time that week, the website’s search was down. As one would expect, one of the most important projects, when I joined the team a few weeks later, was to fix our search. We eventually wrote in detail about that new iteration of our search platform, which included extracting search and indexing logic to their own microservices. There is one relatively small change never previously discussed that is relevant to the object identity topic: what to do when a list contains objects from different types.
One of the new features introduced with the new search was a good experience for universal search, i.e. a single search would return tracks, comments, users, and playlists matching the specified criteria in a single result. Apart from the many search-specific infrastructure and application architecture challenges we had to face, our public and internal APIs had to be changed. Previously, our search results were like this illustrative example:
{
"results": [
{
"id": 4057212,
"created_at": "2010/11/02 09:24:50 +0000",
"user_id": 3207,
"duration": 1546,
"sharing": "public",
"description": "a couple of field recordings",
"genre": "",
"title": "Field Recordings"
},
{
"id": 678682,
"created_at": "2012/01/12 19:22:01 +0000",
"user_id": 5577,
"duration": 1281,
"sharing": "public",
"description": "what sound bananas make",
"genre": "bananatronic",
"title": "Big B"
},
]
}
Given the client had to say what type of object it was interested in explicitly, they can guess what the results represent—in this case, tracks. Once you have a list containing more than one type of object, this wouldn’t be so clear anymore. Maybe you could try guessing the type based on the attributes of the object, but even this way you’d end up with many cases where objects have very similar shapes, for example when trying to distinguish tracks from playlists.
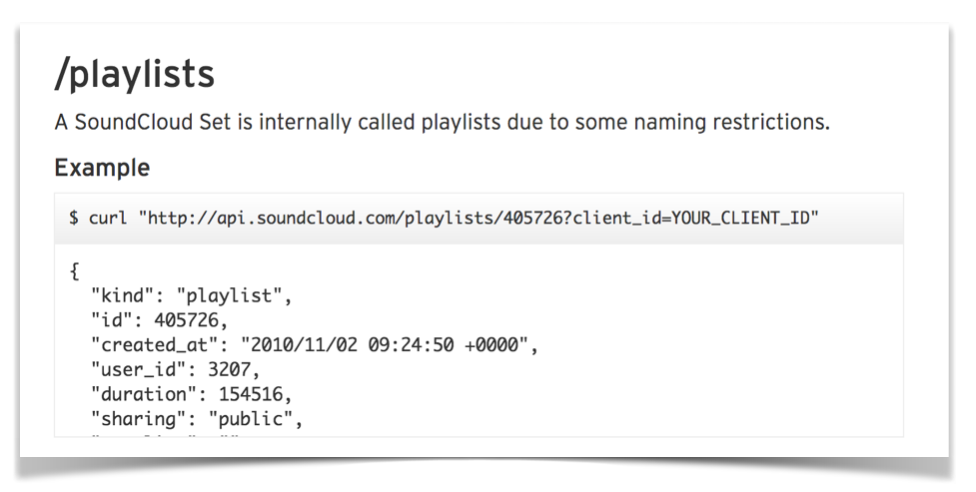
The solution found by the search team was to add a new attribute, which they called kind, to the results. SoundCloud’s public API has changed a lot over the past few years, but as of writing, you can still see this attribute in several of their endpoints:
There were several challenges with this approach.
Something I’ve personally failed at in this area was to make it such that we had a single way to identify the type of an object. Sometimes the type of an object was defined by that kind attribute, but some other endpoints would use other attributes like type. Even if we were fewer than thirty programmers working in the same Berlin office one should never underestimate Conway’s Law…
But even if we had a single attribute and term used across our systems and APIs, the new field fundamentally change the way we think about object identity. As mentioned previously, object identity is what allows us to identify an object uniquely and to verify if two instances are the same object or not. Once you have objects from different types, id isn’t enough to distinguish an object anymore. In the example above, your identity becomes the combination of id and kind. The simplicity of a single id field is gone, and every time a service or API receives an identifier as input or returns one as output you must also return a description of the object type.
pURIs: Borrowing a solution from the Internet
When facing the problems above, my team at SoundCloud started exploring alternatives that would allow for us to have simple, scalar values that were still rich enough to act as good identifiers across our hundreds of microservices. Reading through decades of industry work on the matter, we found something simple that could help us: Uniform Resource Names, or URNs. URNs were a type of Uniform Resource Identifiers (URIs) that, as opposed to URLs, were only concerned with the identifier for a resource, but not with how to locate it.
The specification allowed for us to create structured identifiers that would contain information about the object’s type. This means that instead of the confusion created by an id of 123, we would have ids that looked like:
urn:tracks:123
urn:users:123
urn:comments:123
urn:artwork:123
urn:playlists:123
As we iterated on our approach, we have decided to follow more recent recommendations and not limit our identifiers to the deprecated concept of URN. Instead, we have decided to make them a type of URI with a private schema. This led us to identifiers that look like:
soundcloud:tracks:123
soundcloud:users:123
soundcloud:comments:123
soundcloud:artwork:123
soundcloud:playlists:123
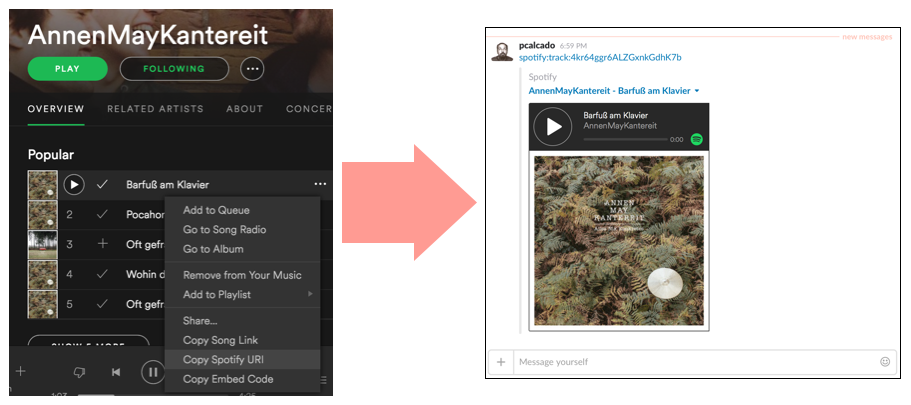
It turns out that we were not the only Swedish-born startup trying to disrupt the music industry doing that. In fact, Spotify has had URIs as a strong part of their user experience and integrations for many years:
Why are these pseudo-URIs?
URIs are owned and managed by the W3C and IETF. They are documented and specified in countless RFCs and other documents that deal with all sorts of use-cases and impedance mismatches that happen when you govern a standard used in such open ecosystem as the Internet. To properly understand those one needs to learn about XML, QNames, CURIE, and many other concepts and standards.
While I would never suggest that you consciously break compatibility between the URIs you use internally and the standards, I strongly suggest that you make the explicit trade-off of prioritising your own productivity and simplicity versus compatibility. In practical terms, this means that you should probably make sure that you have well-known and followed the rules about how you model your URIs, but do not invest a lot of time trying to cater for all possible features and corner cases that the W3C and IETF have to handle.
We make no guarantees that our implementation is compatible with the Internet standards, but if you know the standards you will hopefully find the usage here intuitive. This is why I like to call this usage of the URI concept a pseudo-_URI (_pURI), trying to make it clear that this usage is different from what one would expect.
Creating a good-enough pURI spec
RFC 3986 defines the syntax for URIs as following this structure:

Where a scheme describes a namespace. In theory, each scheme could define their own rules about how the rest of the URI is formed, but for pURIs the recommendation is that an organisation standardise a single format that all pURIs should follow irrespective of their scheme.
In my experience, a good-enough specification for a pURI should specify:
- How many segments are there and if teams and service owners can add new segments
- What is the encoding and escaping expected for the text
- What in the identifier should be treated as opaque data as opposed to parts where consumers can make assumptions about data formats
So far my favourite format is reasonably simple:
namespace:collection:identifier
- It is composed of three segments, each separated by a
:. - Each segment is composed of a stream of case-insensitive characters following normal Percent-encoding rules
- Segments cannot be added or removed, but teams and services might end up defining their own sub-schemes using special characters (e.g.
bobsburgers:meats:chicken-prime,bobsburgers:meats:chicken-leftovers,bobsburgers:meats:beef-prime) - The first segment is the scheme, which I prefer calling namespace. This is used to describe the organisation that owns that concept. This segment can be used to identify if two objects belong to the same owner.
- The second segment is a collection. It describes the type of object. This segment can be used to identify if two objects have the same type.
- The third segment defines the identifier for that object. An identifier can be any stream of allowed characters, but an identifier must be unique within the namespace and collection.
- Any two objects with the same namespace, collection, and identifier are considered to be equal.
The benefits of namespaces
Although teams and service owners have some degree of freedom in defining subgrammars within each segment, this feature is seldom useful. That’s why I like to call the first segment namespace instead of scheme, as I believe that the biggest benefit of that component isn’t in syntax rules but defining a scope for objects.
This might sound like overkill at first, but let’s look at the Spotify example again. If instead of spotify:track:5Z4wPH4v6uxS5nA9OmRnRq they had only track:5Z4wPH4v6uxS5nA9OmRnRq. In this case, when I paste that text on a channel like above how would Slack know that I am referring to a Spotify track, as opposed to something from some other music platform?
But we can find similar challenges even within our own organisation. Let’s say, for example, that you are a news organisation that publishes articles. Articles usually have pictures, and your writers usually take pictures to illustrate the pieces they produce. One interesting challenge arises when you also need to deal with pictures coming from a third-party source, like a stock photo provider. If you have a simple pictures namespace you will need to find some other way to figure out if a given picture’s rights belong to you or not. Even more interesting, if you and the third-party entity both generate identifiers the same way, e.g. using auto increment integers, you can have conflicts.
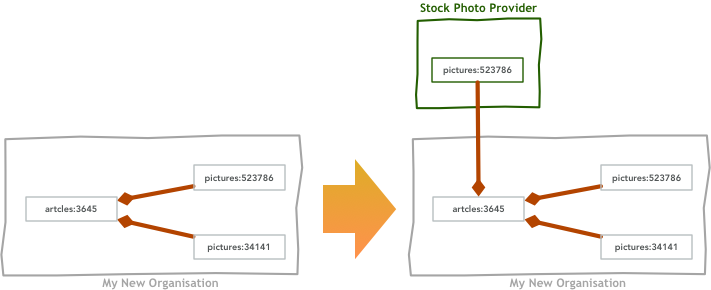
Whenever situations like the above arise I usually see programmers trying to fix the issue by creating two different namespaces. In the example above, we could have own-pictures:523786 and 3rd-party-pictures:523786. Every time I see solutions like these, though, upcoming features and use cases evolve in such manner you’ll find yourself parsing the namespace across many different services. Instead of trying to hack this extra bit of information in a limited shape, I would much rather add the namespace as a third component and avoid having to parse segments altogether.
Simpler namespaces like these work well for global standards, like ISBN, but fall short when there isn’t a single organisation that assigns identifiers to objects. This is the main reason for me not to use the CURIE syntax, as it doesn’t allow more than one level of namespacing.
Namespaces and collections should not be bound to systems
When first implementing the concept, it is common for teams to think of pURIs shaped like this:
my-org:mybillingsystem-bills:122s112A
Where mybillingsystem is how your company calls your homegrown billing system. There are valid reasons for a team to try and add a prefix to the collection above—I wouldn’t be surprised if your domain deals with different kinds of bills. The main problem with the example above isn’t necessarily the existence of a prefix on the collection, but that this prefix is strongly coupled to a specific system.
As we’ve discussed in this blog before, the term microservices isn’t very well defined. Still, something that happens a lot in architectures described as based on microservices is that new systems come and go all the time. In general, data tends to live for much longer than code, and with microservices code tends to live for an even shorter period. Soon enough, mybillingsystem will be replaced by myevenbetterbillingsystem and you will either have legacy pURIs or have to go through a big and useless migration between two collections that are, effectively, the same.
In the example above, if you have more than one type of bill in your system you should avoid using any technical term to distinguish them. Instead, use a domain concept, something straight out of your Ubiquitous Language. Something like:
my-org:revenue-bills:122s112A
Storing pURIs efficiently
When a team is introducing pURIs, the first reaction of a database expert is typically to get very angry. One very good reason to use database primary keys is how efficient they are. They tend to be reasonably small integers, which databases and programming languages can deal with very well, but even more sophisticated types like UUIDs are usually handled at the native level by databases.
But reality is that you don’t necessarily have to lose storage efficiency to use pURIs. One solution to this problem is to provide a clear mapping function between your pURIs and how they are stored in a database.
For example, if you have pURIs like this:
my-org:revenue-bills:12323
my-org:payable-bills:249889393
What you need is to provide a set of functions able to map between these formats and whatever optimal way you want to store them in:

This issue isn’t very different from the general impedance mismatch between Object-Oriented systems and relational databases, and you can solve it by applying the same methods, like those well-documented by Scott Ambler many years ago:

One way in that pURIs used across microservices are different from objects in monolithic Object-Oriented systems is in that in the latter you often have control over how many types, usually classes exist. You don’t have this control when using microservices, and you should not make assumptions about how many collections or namespaces exist or what are they. That’s why I wouldn’t suggest implementing the Replace Type Code with Booleans pattern suggested by Ambler. When dealing with microservices, you need to apply the Tolerant Reader patterns all the way down to your storage.
Notice that similar mapping functions can help you minimise the amount of data transmitted to client applications, especially when dealing with customers with bad networks like when using mobile phones. A BFF is a great place to store these mapping functions.
Acknowledgements
During my time at SoundCloud, the pseudo-URI/URNs architecture was maintained by the Core Engineering team composed of Kristof Adriaenssens, Bora Tunca, Rahul Goma Phulore, Hannes Tydén, Vitor Pellegrino, Sam Starling, and I.
Deep Kapadia, Greg Gigon, Bruno Carvalho, and Thompson Marzagão gave feedback on drafts of this article.