How we ended up with microservices.
Microservices are a thing these days.
When I was at SoundCloud, I was responsible for the migration from a monolithic Ruby on Rails application to a constellation of microservices. I’ve told the technical side of this story multiple times, both in presentations, and as a multi-part series for SoundCloud’s engineering blog. These engineering bits are what people are most interested in hearing about, but recently I realised I never explained to a wider audience how we ended up using microservices to begin with.
I am sorry to disappoint my fellow techies, but the reason we migrated to microservices had to do much more with productivity than pure technical matters. I’ll explain.
Note: This post definitely has a lot of revisionism, and, in trying to make it easier to understand, oversimplifies a fairly chaotic chain of events into a linear timeline. Nevertheless, I believe it paints a pretty good picture of my first couple of years at SoundCloud.
The Next project
When I first joined the company, the most important project we had at play was what we internally called v2. This was a complete revamp of our website, and it was released under the brand name The Next SoundCloud.
I first joined the back-end team, the App team. We were responsible for our monolithic Ruby on Rails application. At that time we didn’t call it legacy, we just called it the mothership. The App team owned everything in the Rails app, including the old user interface. Next was a single-page JavaScript web application, and we followed the standard practice for the time and built it as a regular client to our public API, which was implemented in the Rails monolith.
These two teams, App and Web, were really isolated—we even lived in separate buildings across Berlin. We pretty much only saw each other during all-hands meetings, and our main communication tools were issue trackers and IRC. Still, if you were to ask anybody from any of the teams about how our development process worked, they would describe something like this:
- Somebody has an idea for a feature, they write a couple of paragraphs and draw some mockups. We then discuss it as a team.
- Designers shape up the user experience.
- We write the code.
- After a little testing, we deploy.
But somehow there was a lot of frustration in the air. Engineers and designers complained that they were overworked, but at the same time product managers and partners complained they could never get anything done on time.
Being a tiny consumer business, we really needed to make sure we were launch partners (you know, those partners Apple and Google show on a slide whenever they release a new product) for as many companies as we could, as this meant free press and growth. We also really needed to release Next in private beta before christmas, otherwise the holidays season would push all of our initiatives to the second quarter of the new year, as we didn’t want any new feature to be released before the new website was live. To make it to the keynote slides and make sure we don’t waste a whole quarter of feature launch, we needed to start hitting some deadlines for a change.
This was about the time we decided to try and understand exactly what our organically-grown process had become.
Process hacking
Prior to joining SoundCloud I had spent way too many years as a consultant, and one of the most valuable tools I’ve brought from this dark past was the concept of creating a Value Stream Map. I won’t bore you with the whys and hows for this technique, but if the process described below sounds interesting at least now you know what to google for.
With a combination of informal interviews with different engineers and gathering data from our multiple automated systems, we were able to draw a map of our actual process, as opposed to the process we thought we had. I can’t show you the actual document, but it wasn’t too far away from the fictional example below:
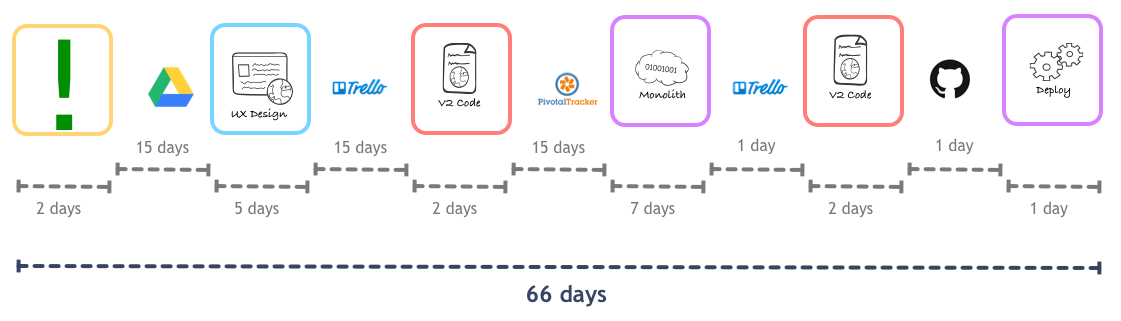
The actual flow was something like this:
- Somebody comes up with an idea for a feature. They then write a fairly lightweight spec, with some screen mockups, and stores that in a Google Drive document.
- The spec stays in this document until somebody has time to actually work on it.
- The very small design team would get the spec and design the user experience for it. This would then become a card in the Trello board owned by the Web team.
- The card would sit on the Trello board for a while, at least a 2-weeks iteration, until an engineer was free to pick it up.
- The engineer would start working on it. After converting the design into a proper browser-based experience using fake/static data, the engineer would write down what changes in the Rails API they would need for this experience to work. This would go into Pivotal Tracker, the tool of choice for the App team.
- The card would sit on Pivotal until somebody from the App team was free to look at it, often taking another two-week iteration.
- The App team member would write the code, integration tests and everything required to get the API live. Then they would update the Trello issue, letting the Web team know their part was done.
- The updated Trello card would sit in the backlog for a while more, waiting for the engineer in the Web team to finish whatever they started doing while waiting for the back-end work.
- The Web team developer would make their client-side code match whatever kinks from the back-end implementation, and would give the green light for a deploy.
- As deployments were risky, slow, and painful, the App team would wait for several features to land into the master branch before deploying it to production. This means the feature would be sitting in source control for a couple of days, and that very frequently your feature would be rolled back because of a problem in a completely unrelated part of the code.
- At some point, the feature finally gets deployed to production.
There would be heaps of back-and-forth between those steps as people needed clarification or came up with better ideas, but let’s ignore this for now.
In total, a feature would take about two months to go live. Even worse: more than half of this period would be spent either waiting time, i.e. some piece of Work In Progress waiting to be worked on by an engineer.
Tools like the map above make it easy to spot obvious weird steps in one’s process. One low-hanging fruit we found just by looking at this was the idea that we should adopt a release train for the monolith. Instead of waiting until we had enough features for a deploy, we would start deploying every day, just after standup, irrespective of how many features had landed into master. This was still far away from Continuous Deployment, but trimmed our cycle a little bit:
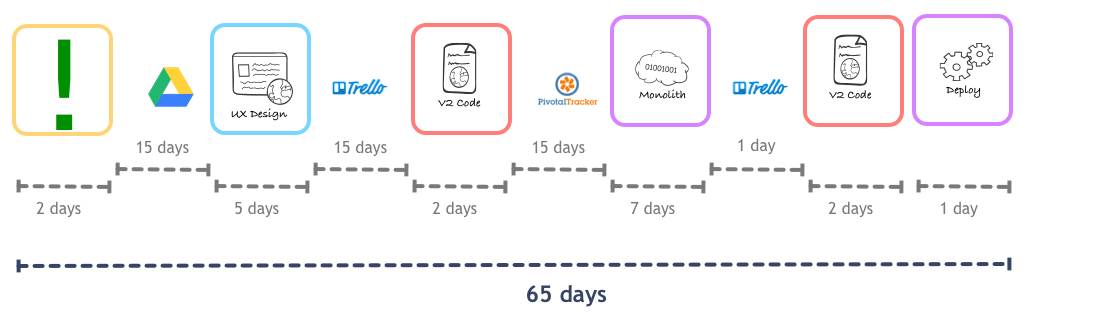
Low-hanging fruits are great motivation drivers, but in our case the main elephant in the room was clearly all the dance between front-end and back-end development.
The way we divided work between Web and App teams completely alienated back-end developers from the actual product. They would get frustrated, and feel they don’t have a say on the product at all. The perception was that they were just “told what to do by the pixel pushers”. In a market where there’s so much more demand for experienced developers than supply, treating your team like this isn’t really smart.
But the problem we will focus on today is that out of the 47 days spent in engineering, only 11 days are doing actual work. The remainder is wasted in queues and general waiting time.
There is something to be said about how much waiting time was due to waiting for a new iteration, but even moving to an iteration-less process, like variations of Kanban, didn’t help reduce this much.
We then decided to do something controversial: pair back-end and front-end developers and make this pair be fully dedicated to a feature until its completion. We only had 8 back-end to 11 front-end engineers, so the contention around this strategy was due to the perception that we needed to have the front-end developers doing as much work up-front as possible, so that the back-end people would spend as little as possible on each feature. This setup was intuitive, but the process mapping showed us that it was actually very counter-productive. Even discounting the back-and-forth between front and back-end developers, we still have too long waiting time until something is actually live in production!
We decided to try this out first with a single pair, extending to others over time. The new flow was like this:
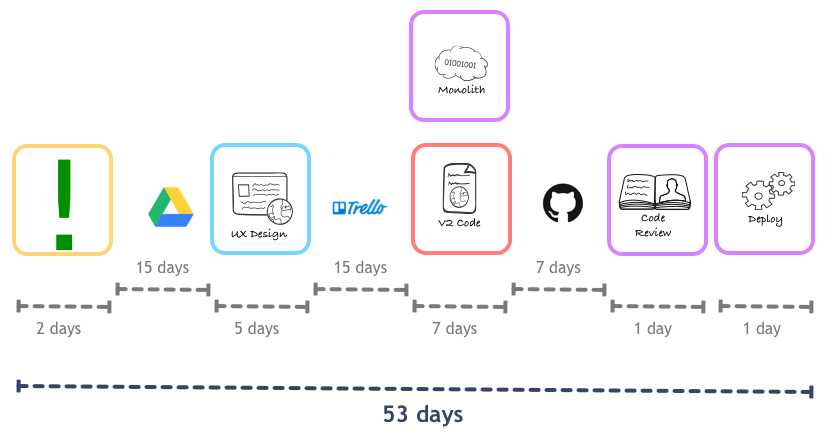
Individually, each person ended up spending more time doing work per feature. This was irrelevant, though, as because they were working at the same time they were able to get the end-to-end coding done in much less time than before. The caveat here was that, given the back-end developer wasn’t as close to the rest of the App team as before, there was a mandatory code review (aka. Pull Request) process required before the change landed on the master branch of the Rails app.
The reduction was quite a feat, and we decided to try and do the same with other steps in the process. We got designer, product manager, and front-end developer working close to each other in the very conception of a feature, and the cycle time was reduced even more:
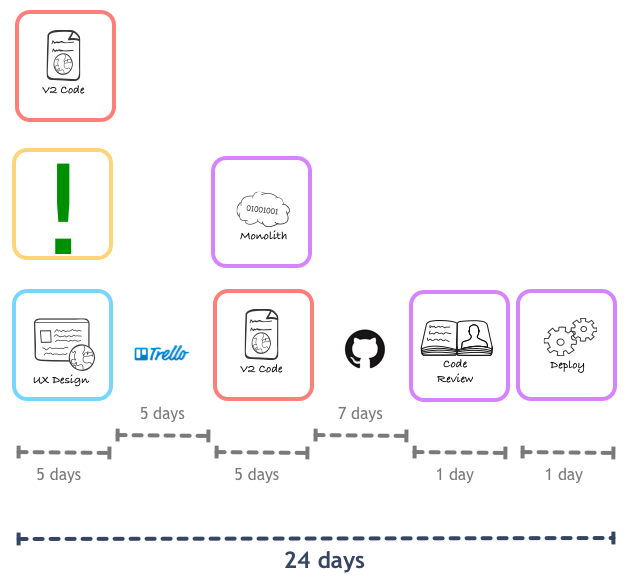
Pretty solid reductions here. With the much shorter workflow, we could easily launch the first release of Next way ahead of our deadline. We kept on iterating in the pairing of people from different disciplines, eventually leading to the feature team structure SoundCloud applies today. But this is a topic for another day, right now we need to focus on what was up with that long Pull Request queue.
From mothership to legacy
One of the things that got me the most excited about joining SoundCloud was the engineering culture. Most of it sounded very similar to what I was used from ThoughtWorks projects, but there was one aspect that was brand new to me: mandatory code reviews.
This was 2011, and all startups were trying to replicate the Github model, best summarised by Zach Holman’s How GitHub Uses GitHub to Build GitHub talk. After so many years using and advocating for trunk-based-development, I couldn’t wait to see how successful companies like SoundCloud and Github used this very different approach.
Back then, all engineers in the App team would sit around the same table, share the same backlog of tasks, and be generally very close to each other. The monolith’s code base was already old, mature, and boring. We all followed the same principles and patterns across the whole code base, commits would just extrapolate the existing design and bring no surprises. This made the Pull Request process mostly a formality, people would spend less than an hour reviewing a submission.
As more and more people left the close knit group to pair with people from the Web team in developing Next features, the informal communication channels broke down. Problematic deploys, caused by misunderstanding on what was being deployed or how some feature was designed, became frequent. As it usually happens with human beings, after one too many of these we decided that the solution would be to enforce a more strict process around merging changes. From now on, before making it to the master branch and eventually deployed, all changes would have to be “formally” approved by a second engineer.
As the map above shows, this ended up creating a long wait for Pull Requests to make it to production. In trying to fix this, the first step we took was to make it such that everybody would spend at least one hour a day reviewing Pull Requests coming from outside the team—i.e. from people working on Next. This didn’t reduce the queue much, and eventually we realised that some smaller Pull Requests were reviewed by many people whilst the largest Pull Requests (and Pull Requests coming from Next were usually large) were not reviewed by anybody until a product manager yelled at the team. Larger changes required a lot of time to be reviewed and, due to the spaghetti nature of our Rails code, were very risky. People avoided these big Pull Requests like the plague.
We got together and decided that developers working on Next features were to split their work in smaller, more manageable Pull Requests. This worked well in the sense that each Pull Request would be reviewed and merged quickly, but at the same time the artificial breakdown of a single feature into smaller Pull Requests made it so that the reviewer could not see the forest for the trees: sometimes a chain of good commits hide a dangerous architecture mistake. We identified the need for better user stories, but training our staff would take a while and we needed a short-term solution to survive as a business.
The decision was to apply the oldest trick in the book: pairing. See, our requirement was that code should be reviewed by another developer. With pair programming we have real-time reviewing at all times, which means each commit gets and automatic +1. Most people were happy with pairing, and those who weren’t happy were given the option to keep working by themselves, but only on tasks not related to the Next project.
We started trying it out with a couple of pairs, but an interesting issue held us back. Turns out that the monolithic code base we had was so massive and so broad no one knew all of it. People had developed their own areas of expertise and custodianship around submodules of the application. When a pair picked up a card to play, odds were that this pair didn’t have enough knowledge around that part of the code base, so they’d have to either wait for the expert to become available and swap pairs with theirs or pick another, often lower priority, card. Both options were bad.
A meme around the company was “everything is fun and games until someone has to touch the monolith”.
The irreducible complexity of the monolith
To shave those 8 days off our lead time, we would need to take a step back and ask ourselves why we needed all this Pull Requests to begin with. As we found out more about our own process, our thinking evolved like this:
- Why do we need Pull Requests? Because we knew, from years of experience, that often enough people make silly mistakes, push the change live and takes the whole platform down for hours.
- Why do people make mistakes so often? Because the code base is too complex. It’s hard to keep everything in your head.
- Why is the code base so complex? Because SoundCloud started as a very simple website, but over time it grew into a large platform. We have a lot of features, various different client applications, very different types of users, sync and async workflows, and huge scale. The code base implements and reflects the many components of a now complex platform.
- Why do we need a single code base to implement the many components? Because of economies of scope. The mothership already has a good deployment process and tooling, has a battle-tested architecture against peak performance and DDOS, is easy to scale horizontally, etc. If we build new systems, we will have to make build all these for every new system.
- Why can’t we have economies of scale for multiple, smaller, systems? Uhm…
The fifth question took a bit longer to answer. Our collective experience and a survey of our peers had shown us that there could be two possible alternatives:
- (A) Why can’t we have economies of scale for multiple, smaller, systems? Is not that we can’t, but it won’t be as efficient as if we keep everything in one code base. We should, instead, build better tooling and testing around the monolith and its developer usability. That’s what Facebook and Etsy do.
- (B) Why can’t we have economies of scale for multiple, smaller, systems? We can. We will need to do some experimentation to find out what tooling and support we need. Also, depending on how many separate systems we build, we will need to think economies of scale as well, but this is how Netflix, Twitter, and others build their systems.
Each approach had their proponents, and neither sounded obviously right or wrong. The biggest question marks were around how much effort each approach would require. Money and resources weren’t a problem, but we didn’t have enough people or time to invest in anything big-bang. We needed a strategy that could be implemented incrementally, but start delivering value from the very beginning.
We took another look at what we had in hands. We always thought of our back-end system in very simple form:
This mindset makes it obvious to implement this big box as a single monolithic piece. As we found out in our self-questioning, though, things weren’t as simple as the picture above leads you to believe. Actually, if you open that one black-box you will realise that our system was more like the (very simplified) image below:
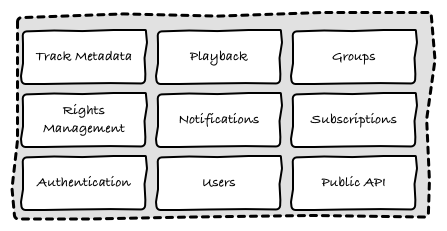
We didn’t have a single website, we had a platform with multiple components. Each of these components had their own owners and stakeholders, and independent life cycle.
For example, the subscriptions module was built once, and would only be modified when our payment gateway asked us to change something in our process. On the other hand, the notifications and other modules related to growth and retention would suffer daily changes as our young startup tried to acquire more users and content.
They also had very different service level expectations. Nobody would die if we didn’t have notifications for one hour, but a five minutes outage in the playback module was already enough to hit our metrics hard.
While exploring option (A), we came to the conclusion that the only way to make the monolith work for us would be to make these components explicit, both in our code and deployment architecture.
At the code level, we needed to make sure that a change made for a single feature could be developed in relative isolation, not requiring us to touch code from other components. We needed to be reasonably sure that the change didn’t introduce bugs or changed runtime behaviour in non-related parts of the system. This is an old problem in the industry, and we knew that what we had to do was to make our implicit components explicit Bounded Contexts, and make sure we are mindful about what module can depend on which other.
We discussed using Rails engines and various other tools to implement this, it would look a bit like this:
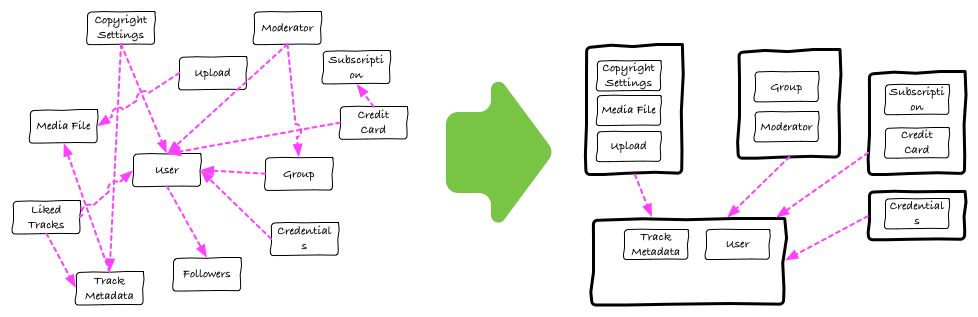
At the deployment side, we would need to make sure that a feature can be deployed in isolation. Pushing a change to module to production should not require a new deployment of unrelated modules, and if such deployment went bad and production was broken the only feature impacted should be the one that suffered the change.
To implement this, we thought about still deploying the same artifact to all servers, but use load-balancers to make sure a group of servers was responsible only for a single feature, isolating any problems with this feature and servers from the others:
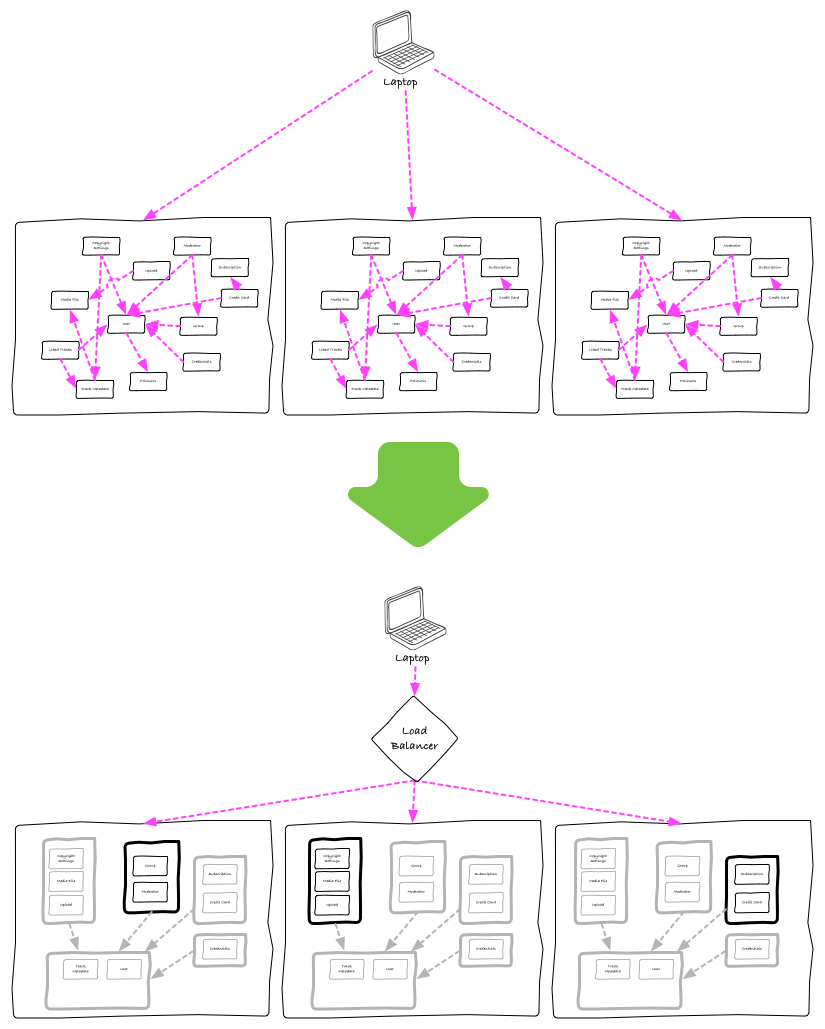
The work in getting those done wouldn’t be trivial. Even if the above didn’t require any departure from the tech stack and tooling we had been using, the changes brought their own questions and risk.
But even if everything went smoothly, we knew that the current code for the monolith had to be refactored anyway. The code had suffered a lot during the past few years, tech debt everywhere. Besides the mess we made ourselves, we still had to update it from Rails 2.x to 3, and this is a big migration effort in itself.
Those considerations led us to re-consider option (B). We thought it wouldn’t look too different:
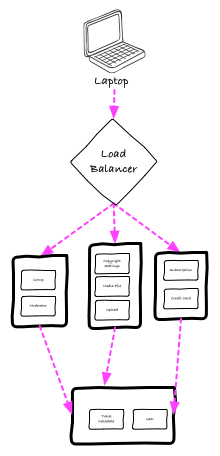
But at least we were able to benefit from the approach from day zero. Anything new we were to build would become a greenfield project, and the delay introduced by Pull Requests wouldn’t be necessary.
We decided to give it a try, and eventually built everything required for our first monetisation project as services, isolated from the monolith. The project introduced several big features and a complete revamp of our subscription model, and it was delivered ahead of deadlines by 2 teams of 2 engineers each.
The experience was good enough we decided to keep applying this architecture for anything new we build. Our first services were built using Clojure and JRuby, eventually moving to Scala and Finagle.
Obligatory reference to Conway’s Law
It’s fair to say that almost everything new built on SoundCloud since 2013 uses services. At some point between then and now we started using the word microservices to refer to them, but we didn’t really have it in mind when we first started building on this architecture (the first time the word ‘microservice’ was used in an email at SoundCloud was in 2013, the first services were implemented in 2012).
With the new architecture framework, we were able to reduce our lead time for new features to something that, whilst still far away from the good old days, was much more acceptable for a company trying to play in the highly competitive music industry:
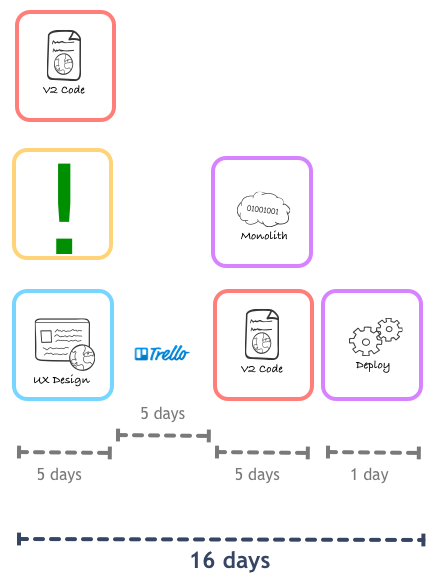
So far so good, but this is for brand new features. Whenever we needed to evolve existing feature, those implemented in the monolith, we were back to the old cycle. Even worse, so many people were spending more time in these new microservices than in the monolith that the number of available reviewers was decreasing, and the Pull Request queue growing larger.
Every time some larger change would be proposed, we made it sure to factor in enough time to extract the old system from the monolith. Somehow it never happened, though. People would still either implement the change in the old code base or create some weird hybrid, where the changes would be implemented in a microservice that was so coupled to the monolith that it might as well be the same system.
At this stage the App “team” acted mostly like a pool of back-end developers who would be paired with people from the Web team, designer, and product managers to work on a feature for some time. People would be jumping from one feature to another all the time, and we realised that we didn’t develop a sense of ownership or autonomy towards any part of the system. Nobody wanted to make the risky investment of extracting some ancient piece of code if they didn’t feel responsible for it. It’s an instance of the old adage: what’s everybody’s responsibility is nobody’s responsibility.
We thought about splitting the pool into smaller teams, focused on specific areas. After spending a lot of time trying to find good logical groupings to form teams around, we couldn’t agree on anything. It was a frustrating exercise, and at some point I just split the group into teams of 3-4 people each, and semi-randomly gave them responsibility over modules.
These teams were explicitly told that they had full ownership over the modules they owned. This meant that they would be on call for any outages related to those, but would also have the freedom to evolve these in any shape they thought reasonable. If they decided to keep something in the monolith, it would be their call. They were the ones maintaining that code anyway.
As you might guess, we saw an exodus from the monolith. Messages, stats, and most of the revamped features we needed for the new iOS app were extracted from the main code base.
Everything was going great, but my semi-random way of splitting teams had one big problem: a single team was responsible for most of the really fundamental features and objects in the ecosystem, things like track and users metadata and the social graph. This team was in constant firefighting mode, and had no incentive to migrate their modules to microservices as this would introduce even more risk and potential outages.
This problem was only addressed recently. We still kept a single team responsible for these objects, but by now our architecture is much more stable, reducing the time required to fire-fighting. We could finally afford having these people facing the extraction of modules from the monolith as a project in itself.
As of today, SoundCloud still has the monolith code live, but its importance decreases every day. It is still in the critical path for many features, but due to a system of stranglers it’s not even Internet-facing anymore. I am not sure it will ever go away, some features it provides are so small and stable it may be cheaper to keep them there forever, but I give it one year until the monolith isn’t on any critical path anymore.
The future
As mentioned in the beginning of the post, this is an oversimplified version of our journey to microservices.
My last 12 months at the company were really focused on the economies of scope and scale we wanted to exploit. As much as I keep repeating that the term microservices doesn’t mean much, the one thing you can be sure when somebody uses this word to describe their architecture is that there will be a lot of services. As organisations grow, they need to be mindful about the fixed cost of each service.
My teams and I have spent a lot of time thinking about how to exploit our constraints and make sure operating this architecture was less expensive and complex than operating the monolith. Hopefully some of the work will be made open-source, so make sure you subscribe to their engineering blog. I’ll also write a bit more about this in future posts.
Over the years we’ve learnt a lot, and as I leave SoundCloud I am fairly certain that the general architecture and team organisation (these things go hand-in-hand) will empower the company in achieving their moonshots over the next few years—maybe until unikernels and the nanoservices they allow for become a thing?