Internal Data Transfer Objects
Note: this article was originally posted in 2008. Re-published as it’s still relevant…
A recurrent question when it comes to real world usage of Domain Models is how to integrate the Presentation and the Business Layer. The design pattern Layers is a disciplined approach to manage dependencies among objects. The question raised is about how to integrate the two topmost Layers in the diagram below.
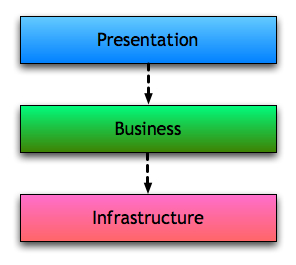
I am not so sure why are there so many doubts about the relationship between these two Layers and not about otherinteractions, like when talking to the Persistence. For me it iss exactly the same: the bottom Layer has an API and the top Layer uses that API to perform its task. The objects received and returned by the API are just regular objects that abstract implementation details about themselves and the Layer they come from. The API will often be implemented as a Façade and the objects returned from it will be proper objects, with state and behavior.
But not everyone think like this. A common technique is to use a Data Transfer Object as the communication medium between those Layers.
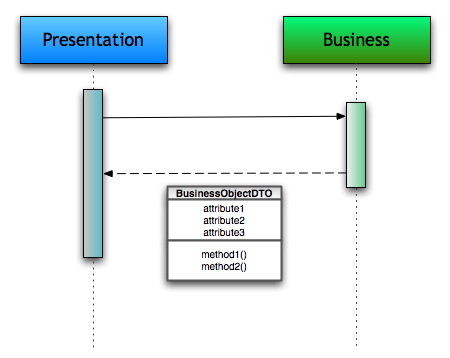
I think that this is not only overkill but has originated some of the most confusing architectures in systems I’ve had access to.
DTO Quick Intro
Before getting to what may lead people into thinking that the Data Transfer Object is a good solution for the “problem”, let’s revisit what the patter is all about.
Suppose you have two nodes (e.g. Virtual Machines, processes, servers, web services… “node” here means something that has its own address space) and want them to share objects between them.

A common pattern is to send a proxy or copy of the object to the client. The problem is that, if you followed proper Object-Orientation guidelines, the object sent will rely on other objects to perform its tasks. Those objects may not have been copied to the new server, therefore operations performed by the local proxy/copy may incur in expensive RPC or IPC calls for doing even the most stupid things, like calling a toString().
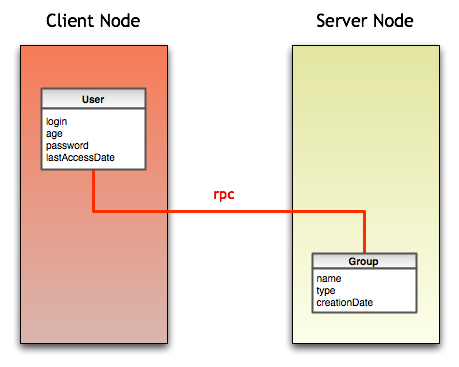
The Data Transfer Object as catalogued by Martin Fowler is a Distribution Pattern in which you wouldn’t send only a proxy/copy of the object to the client, but a coarser grained object that packs pretty much everything that the object will need to perform its tasks.
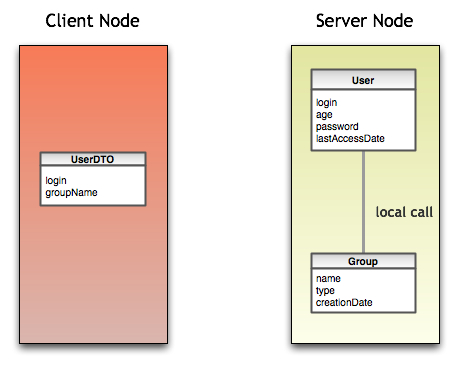
The coarser grained object is optimized for distribution. I like to refer to it as a .tar.gz version of the object.
This technique has some undesirable effects: suddenly you have to maintain two different hierarchies of objects, with heavy coupling between those, and you need to implement mapping between one hierarchy and the other. The DTO hierarchy is pure accidental complexity, it does not map to any business concept.
We use DTOs only because that’s one of the few ways we know to make distributed computing work. Without them, most distributed systems would be extremely slow and inefficient. DTOs are useful for distributed computing but it is very unlikely that they are needed for local communication, such as interaction among Layers.
I have faced some arguments for internal DTOs before. We’ll address those in the next sections.
“Because MVC Requires that”
There is some generalised confusion about the MVC Pattern in our industry; specially about what Model in it actually means. Let’s revisit the MVC Pattern to see if we can find something some clarity.
The original MVC paper describes Model as:
A Model is an active representation of an abstraction in the form of data in a computing system
When cataloguing the MVC Pattern, Martin Fowler says:
In its most pure OO form the model is an object within a Domain Model. You might also think of a Transaction Script as the model providing that it contains no UI machinery.
In Refactoring, Fowler says:
The gold at the heart of MVC is the separation between the user interface code (the view, these days often called the presentation) and the domain logic (the model). The presentation classes contain only the logic needed to deal with the user interface. Domain objects contain no visual code but all the business logic. This separates two complicated parts of the program into pieces that are easier to modify. It also allows multiple presentations of the same business logic. Those experienced in working with objects use this separation instinctively, and it has proved its worth.
As we can see, there’s no direct relation between Layers and MVC, you can use one without the other.
Using MVC within a Layered architecture is useful, though. Craig Larman explains how MVC can be used to bind layers together:
This is a key principle in the Pattern Model-View-Controller (MVC). MVC was originally a small-scale Smalltalk-80 pattern, and related data objects (models), GUI widgets (views), and mouse and keyboard event handlers (controllers). More recently, the term “MVC” has been co-opted by the distributed design community to also apply on a large-scale architectural level. The Model is the Domain Layer, the View is the UI Layer, and the Controllers are the workflow objects in the Application layer.
So it is possible to use the MVC to organize Layers. Based on the previous paragraphs it is probably possible to draw a picture like this:
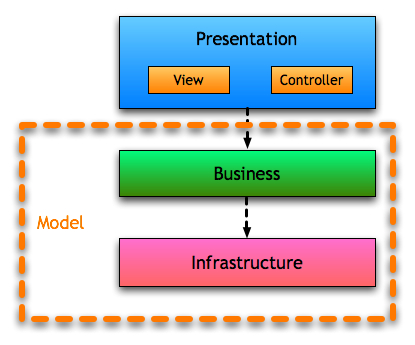
So Layers and MVC are not really related, and our Domain Model plus the whole infrastructure that supports it is our MVC Model. Let’s see how the original MVC related Model and View and see if they have any funny way of talking to each other.
VIEW
DEFINITION
To any given Model there is attached one or more Views, each View being capable of showing one or more pictorial representations of the Model on the screen and on hardcopy. A View is also able to perform such operations upon the Model that is reasonabely associated with that View.
[…]
VIEWS
A view is a (visual) representation of its model. It would ordinarily highlight certain attributes of the model and suppress others. It is thus acting as a presentation filter. A view is attached to its model (or model part) and gets the data necessary for the presentation from the model by asking questions. It may also update the model by sending appropriate messages. All these questions and messages have to be in the terminology of the model, the view will therefore have to know the semantics of the attributes of the model it represents. (It may, for example, ask for the model’s identifier and expect an instance of Text, it may not assume that the model is of class Text.)
So the View not only is tied to the Model, but it also will filter its data and display only what is relevant. That is very interesting because some people use Data Transfer Objects to create different viewpoints.

But, accordingly to the MVC documentation, that is actually the View’s role. That makes the DTO in the previous model completely useless.
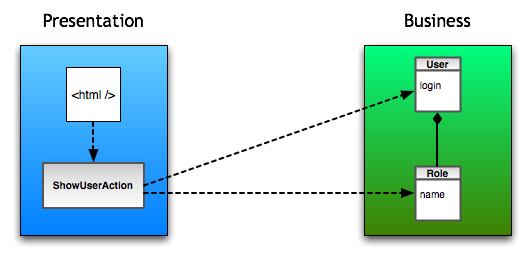
Therefore there’s nothing in the MVC Pattern per se that would require you to use internal DTOs. The View is responsible for accessing the Model and extracting what should be displayed in it.
Using it to Forbid Calls to Dangerous Methods
Another common reason given to justify the internal DTO approach is to forbid UI code (i.e. MVC’s View and Control) to call “business methods”. After some time I figured out that by “dangerous” people usually mean business methods which cause side-effects.

Using a DTO you can hide those methods and, theoretically, people developing UI won’t be able to call them.
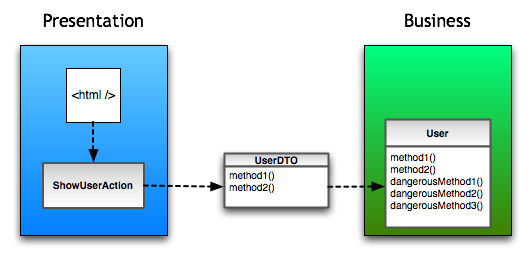
At first this sounds reasonable. When using Layers people should really not call those methods in the Presentation. But my solution for this is: Just don’t call them!. In a responsible team there’s no need for that; developers are not children.
Even if you can’t trust the development team for some reason, if they want to there’s always a way to call those methods. It does not matter how many layers of DTOs you use to hide your business objects a developer can always find a way.
And if you really really want to do such a thing, there are other means. The simplest solution that I can think of is to define checkstyle (or equivalent) rules that forbid those calls and break the build. If you really want to go all fancy just define an interface that doesn’t have the “dangerous” methods and use something like Macker to avoid calls to the implementation.
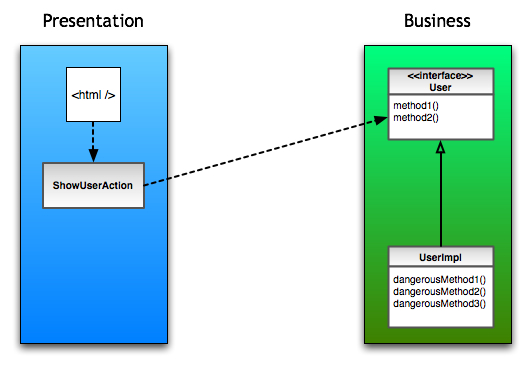
Loose Coupling
Dependency from the Presentation Layer to the Business Layer may require the UI code to be changed whenever there’s a change in the Business Objects. Some people think that this is a problem, and suggest that DTOs between those two Layers could help. I think that a DTO here makes matters worse here.
Without the DTO we would have two components, business and view, and whenever we change business it is possible that we need to change the view.

But adding a DTO the problem gets worse. We now have three components: view, DTO and business. When business changes it is very likely that DTO has to be changed and this will potentially require a change in the view.
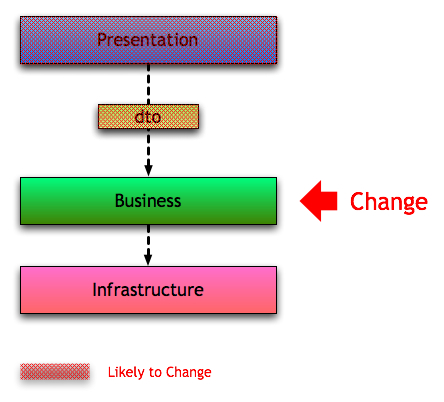
So it doesn’t solve the coupling problem, only adds another coupled component to it. Instead of synchronizing two components you have to do that with three.
The first thing to know is that you can’t avoid coupling, regardless of how much indirection you use. Remember what David Wheeler said:
Any problem in computer science can be solved with another layer of indirection. But that usually will create another problem.
The key to reduce coupling between Presentation and Business is to define a good API. Do not let much detail about how the Business Layer is implemented leak to the Presentation Layer. If your Presentation Layer has to be extremely decoupled from the Domain Model, think about a Presentation Model.
Concluding
As I said before I am not sure why the Data Transfer Object Pattern was choose to integrate Presentation and Business Layers. I think that there are two main drivers:
- Data Transfer objects are often misused as records. Even after decades doing Object-Oriented programming and using OO tools and languages, people still unconsciously run to the Procedural style, where a problem is solved by dumb data structures plus smart procedures. There’s nothing wrong going Procedural if you know what you are doing, but this is never the case here.
- Sun evangelized the use of what they call Transfer Objects (previously called Value Objects) in its EJB 2.x architecture. Those are internal or remote DTOs used to solve some problems introduced by Entity Beans and J2EE technology in general. In newer versions of the EJB spec and in applications that don’t use that technology –e.g. using Hibernate instead- the Pattern is not only not required but also introduces new problems.
The cases presented here for Internal DTOs are those I hear more often. I’m sure there are many others, but I think they all are just examples of people trying to use a Pattern to solve a problem that may not even exist. And of course that there are cases where internal Data Transfer Objects may be valuable. I can’t think of any but I can’t deny they exist…